Hadoop完全分布式搭建
Hadoop完全分布式搭建
集群部署规划
| *Master* | *Slave1* | *Slave2* | |
|---|---|---|---|
| IP | 192.168.1.10 | 192.168.1.1 | 192.168.1.2 |
| HDFS | NameNodeSecondaryNameNode | DataNode | DataNode |
| YARN | ResourceManager | NodeManager | NodeManager |
生成master虚拟机
从最原始的origin主机(关机状态)复制一台虚拟机,虚拟机名为master。
origin主机相关信息如下:
内存:2G
硬盘:30G
OS:ubuntu(64位)
共享设置完成
root用户登录
ifconfig和vim安装完成vim
创建了下面两个文件夹
/root/downloads 文件夹里存放安装包
/root/bigdata 文件夹里存放安装文件(即解压缩后的文件)
防火墙关闭:sudo ufw disable修改master的网卡、虚拟机名、IP地址和主机名
(1)master关机状态下修改网卡,参见课本P82,其中P82的图4.7中的网卡2选择“网络地址转换(NAT)”;
master关机状态下修改虚拟机名,参见课本P83
(2)master开机状态下修改IP地址和主机名,IP等信息见上表,操作步骤可参见课本P84-85
修改IP地址:
root@hadoop:~# vim /etc/network/interfaces
添加以下内容:
auto enp0s3
iface enp0s3 inet static
address 192.168.1.10
netmask 255.255.255.0
broadcast 192.168.1.255
重启网络:
root@hadoop:~# /etc/init.d/networking restart
修改主机名:
root@hadoop:~# vim /etc/hostname
将原来内容删除,改为master.
(3)重启reboot配置/etc/hosts
root@master:~# vim /etc/hosts
192.168.1.10 master
192.168.1.1 slave1
192.168.1.2 slave2配置**SSH**免密登录****
(1)安装SSH
root@ master:~/bigdata# apt-get install ssh
(2)设置免密登录
1)生成公钥和密钥对
root@ master:~/bigdata# ssh-keygen -t rsa
一路回车(三个)即可。
2)查看生成的公钥和私钥。
root@ master:~/bigdata# ll ~/.ssh
3)将密钥加入到公钥中
root@master:~/bigdata# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys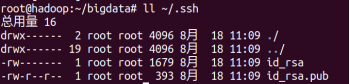
复制master产生slave1和slave2并进行配置
1)将master关机再复制!!!
(2)slave1开机,修改IP地址(192.168.1.1)和主机名
修改IP地址:
root@ master:~# vim /etc/network/interfaces
重启网络:
root@ master:~# /etc/init.d/networking restart
修改主机名:
root@ master:~# vim /etc/hostname
重启slave1,reboot
(3)slave2开机,修改IP地址(192.168.1.2)和主机名;
(4)重启slave2设置master到master、slave1和slave2的SSH免密登录
(1)启动三个节点
(2)在master节点连接到master节点
root@master:~# ssh master
exit退出
(3)在master节点连接到slave1节点
root@master:~# ssh slave1
exit退出
(4)在master节点连接到slave2节点
root@master:~# ssh slave2
exit退出安装JDK
*通过共享文件夹的方式将j**d**k的安装包放在ma**ster**节点的/**root/downloads**文件夹下*
*解压J**DK* *到* */root/bigdata**目录下*
```
root@master:/media/sf_virtualbox-share# cp jdk-8u191-linux-x64.tar.gz /root/downloads
root@master:/media/sf_virtualbox-share# cd /root/downloads
root@master:/downloads# tar -zxvf jdk-8u191-linux-x64.tar.gz -C /root/bigdata/ (这里的C必须大写)/downloads# cd /root/bigdata/
回到/root/bigdata目录下查看:
root@ master:
root@ master:~/bigdata#4.  5. 将解压后的jdk1.8.0_191文件包复制到slave1和slave2 6. ``` root@master:~/bigdata# scp -r /root/bigdata/jdk1.8.0_191/ root@slave1:/root/bigdata/ root@master:~/bigdata# scp -r /root/bigdata/jdk1.8.0_191/ root@slave2:/root/bigdata/
配置JDK环境变量
在 /etc/profile 里配置JDK的环境变量。打开该文件:
```
root@ master:~/bigdata# vim /etc/profile // /etc/profile这个文件是用来存放环境变量的3. shift+g到文件末尾,按i进入插入状态,加入JDK路径: 4. ``` # JAVA_HOME export JAVA_HOME=/root/bigdata/jdk1.8.0_191 export PATH=$PATH:$JAVA_HOME/bin export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
将配置文件复制到slave1和slave2
```
root@master:# scp -r /etc/profile root@slave1:/etc/# scp -r /etc/profile root@slave2:/etc/
root@master:8. 使修改后的文件生效(三个节点都要做) 9. ``` root@master:~# source /etc/profile root@slave1:~# source /etc/profile root@slave2:~# source /etc/profile
安装Hadoop
通过共享文件夹的方式将hadoop的安装包放在master节点的/root/downloads文件夹下
解压hadoop到/root/bigdata目录下
```
root@master:/media/sf_virtualbox-share# cp hadoop-3.1.1.tar.gz /root/downloads
root@master:/media/sf_virtualbox-share# cd /root/downloadsroot@master:~/downloads# tar -zxvf hadoop-3.1.1.tar.gz -C /root/bigdata/ (这里的C必须大写)
4. 将解压后的hadoop文件包复制到slave1和slave2(解压后的文件放到/bigdata中,没解压的压缩包放到/downloads) 5. 配置Hadoop环境变量 6. 在/etc/profile文件中配置JDK的环境变量 7. ``` vim /etc/profile在文件的末尾加入hadoop路径
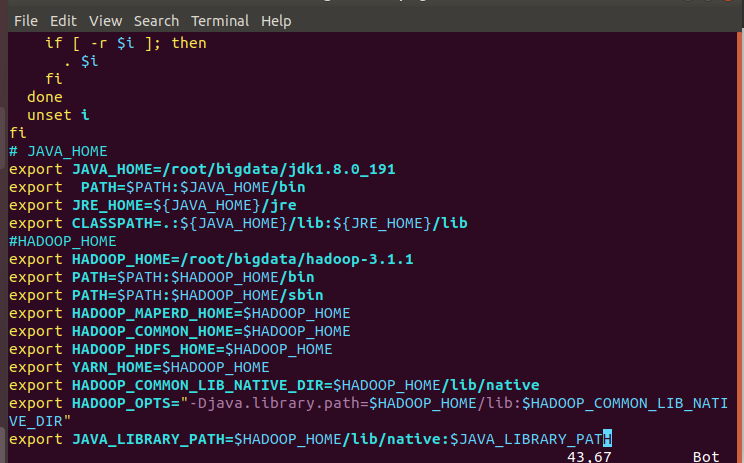
```
HADOOP_HOME
export HADOOP_HOME=/root/bigdata/hadoop-3.1.1
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS=”-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR”
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH11. 保存文件并退出,将配置文件scp到slave1和slave2 12. ``` root@master:~# scp -r /etc/profile root@slave1:/etc/ root@master:~# scp -r /etc/profile root@slave2:/etc/④ 使修改后的文件生效(三个节点都 做):
```
root@master:# source /etc/profile# source /etc/profile
root@slave1:
root@slave2:~# source /etc/profile15. 查看hadoop是否安装成功,在任意路径下输入以下命令来查看hadoop版本 16. ``` hadoop version //注意,这个地方没有-
配置hadoop配置文件(在master节点)
在/root/bigdata/hadoop-3.1.1/etc/hadoop/ 目录下找到所有的配置文件并修改
```
root@master:~# cd /root/bigdata/hadoop-3.1.1/etc/hadoop/3. 创建相关需要的文件夹(三个节点都创建) 4. ``` root@master:~/bigdata/hadoop-3.1.1# mkdir datanode_1_dir root@master:~/bigdata/hadoop-3.1.1# mkdir -p hadoop_data/hdfs/namenode root@master:~/bigdata/hadoop-3.1.1# mkdir -p hadoop_data/hdfs/datanode
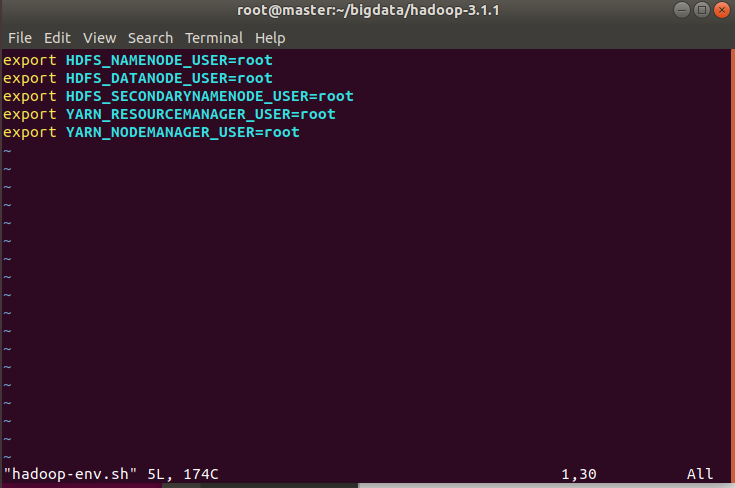
hadoop-env.sh
```
root@master:~/bigdata/hadoop-3.1.1/etc/hadoop# vim hadoop-env.sh
去掉export JAVA_HOME的注释并修改路径:export JAVA_HOME=/root/bigdata/jdk1.8.0_191再添加以下代码:
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root9. 配置core-site.xml 10. ```xml <configuration> <!-- 配置NameNode节点的地址和端口号 --> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <!-- hadoop的临时目录,用来存放hadoop运行时产生的临时文件 --> <property> <name>hadoop.tmp.dir</name> <value>/root/bigdata/hadoop-3.1.1/datanode_1_dir</value> </property> </configuration>配置yarn-site.xml
```xml
yarn.nodemanager.aux-services mapreduce_shuffle yarn.resourcemanager.hostname master yarn.application.classpath /root/bigdata/hadoop-3.1.1/etc/hadoop:/root/bigdata/hadoop-3.1.1/share/hadoop/common/lib/*:/root/bigdata/hadoop-3.1.1/share/hadoop/common/*:/root/bigdata/hadoop-3.1.1/share/hadoop/hdfs:/root/bigdata/hadoop-3.1.1/share/hadoop/hdfs/lib/*:/root/bigdata/hadoop-3.1.1/share/hadoop/hdfs/*:/root/bigdata/hadoop-3.1.1/share/hadoop/mapreduce/lib/*:/root/bigdata/hadoop-3.1.1/share/hadoop/mapreduce/*:/root/bigdata/hadoop-3.1.1/share/hadoop/yarn:/root/bigdata/hadoop-3.1.1/share/hadoop/yarn/lib/*:/root/bigdata/hadoop-3.1.1/share/hadoop/yarn/* <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property>13. 配置mapred-site.xml 14. ```xml <configuration> <!-- 指定MR运行在YARN上 ,取值可为local,classic,yarn之一 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapred.job.tracker</name> <value>master:54311</value> </property> </configuration>配置hdfs-site.xml
```xml
dfs.replication 2 dfs.namenode.name.dir file:///root/bigdata/hadoop-3.1.1/hadoop_data/hdfs/namenode dfs.datanode.data.dir file:///root/bigdata/hadoop-3.1.1/hadoop_data/hdfs/datanode dfs.http.address master:50070 dfs.namenode.secondary.http-address master:9870 17. 配置master文件,这是一个新建文件,将主节点 master 写入进去,以指明哪个节点是NameNode 18. 配置workers,指明哪些是DataNode 19. ``` root@master:~/bigdata/hadoop-3.1.1/etc/hadoop# vim workers 将所有的DataNode节点的主机名写进去,一个占一行。 slave1 slave2将hadoop相关配置复制到slave1和slave2上
```
scp -r /root/bigdata/hadoop-3.1.1/etc/hadoop/ root@slave1:/root/bigdata/hadoop-3.1.1/etc/
scp -r /root/bigdata/hadoop-3.1.1/etc/hadoop/ root@slave2:/root/bigdata/hadoop-3.1.1/etc/## 在master上格式化Namenode 1. ``` root@master:~/bigdata/hadoop-3.1.1/bin# hdfs namenode -format注:在格式化之前,首先要查看是否有一些临时文件夹,如果有(一般是之前格式化产生的),需要删除。这些临时文件有:
*/root/ bigdata/hadoop-3.1.1/**datanode_1_dir* *里面的全部内容*
*/root/ bigdata/hadoop-3.1.1/**log**s* *整个l**ogs**文件夹*
*/root/ bigdata/hadoop-3.1.1/**h**adoop_data/hdfs**/**namenode* *里面的全部内容*
*/root/ bigdata/hadoop-3.1.1/**h**adoop_data/hdfs**/**datanode* *里面的全部内容*
将这四项删除,再格式化,否则datanode可能不显示。
在可视化的方式下删除,找到,直接DELETE键删除即可。三个节点都删除。

web端查看HDFS文件系统和YARN
- 查看hdfs,在Ubuntu内的火狐浏览器的地址栏中输入
- ```
http://master:500703. 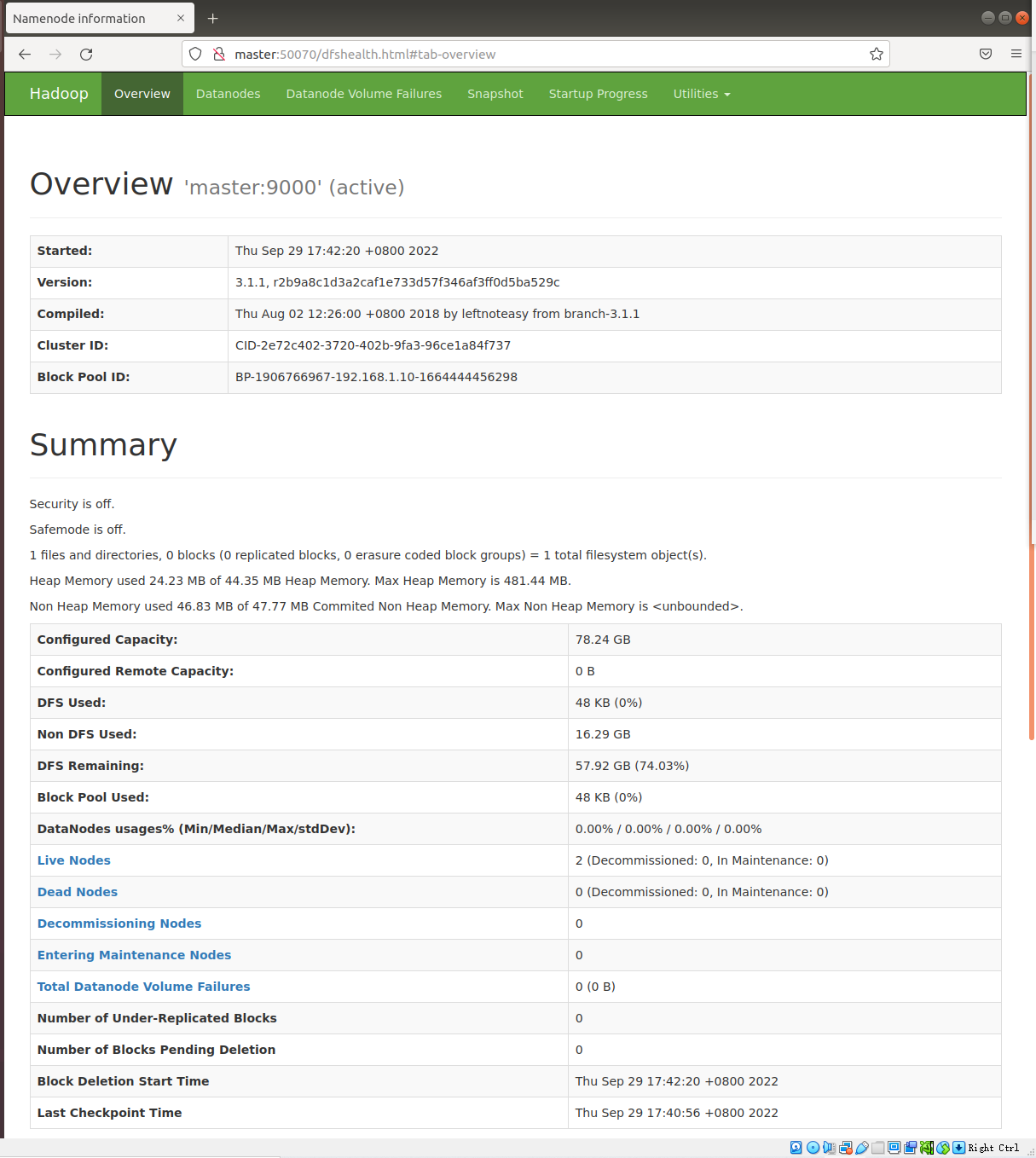 4. 查看yarn,在浏览器中输入 5. ``` http://master:8088/ -
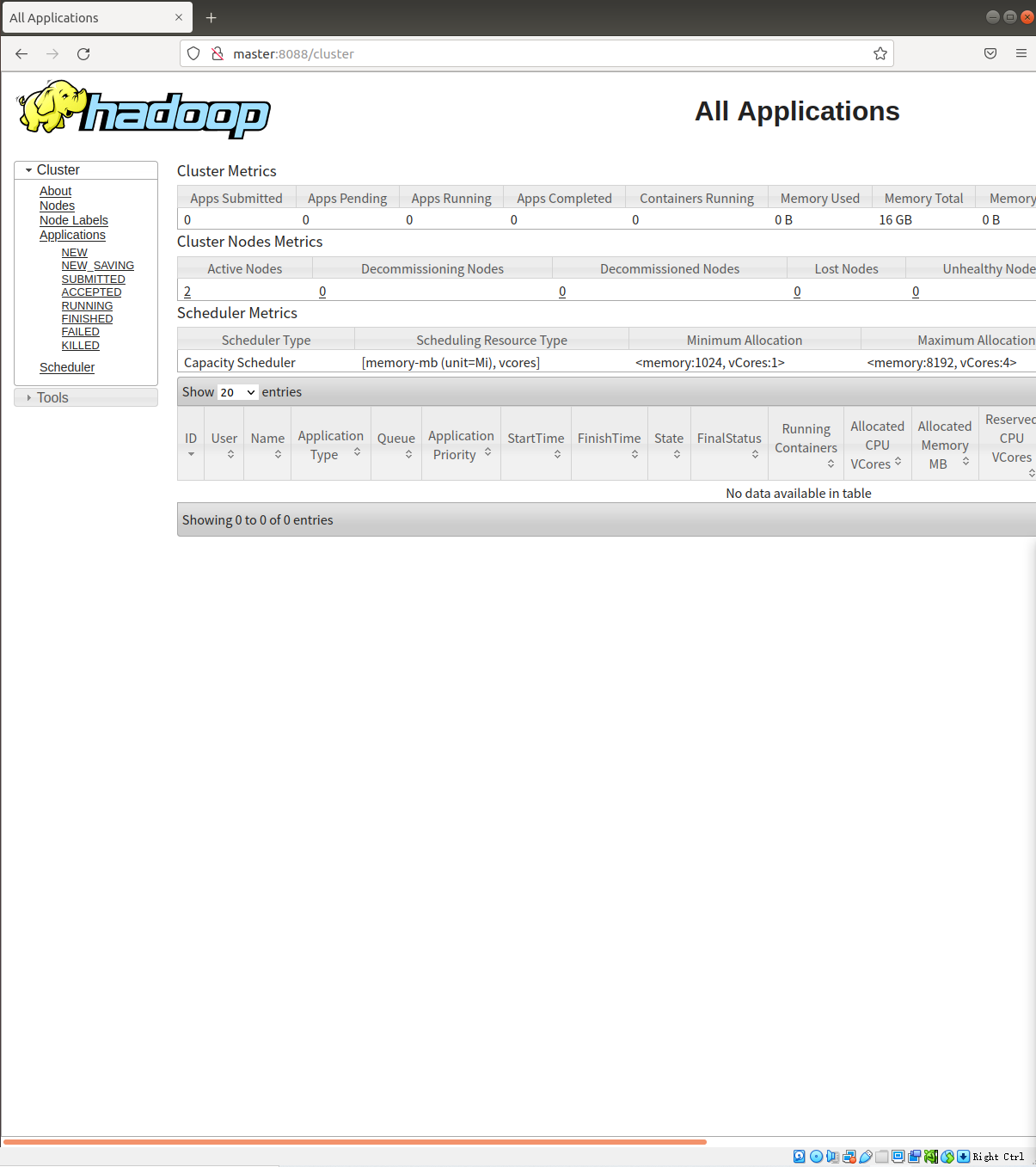
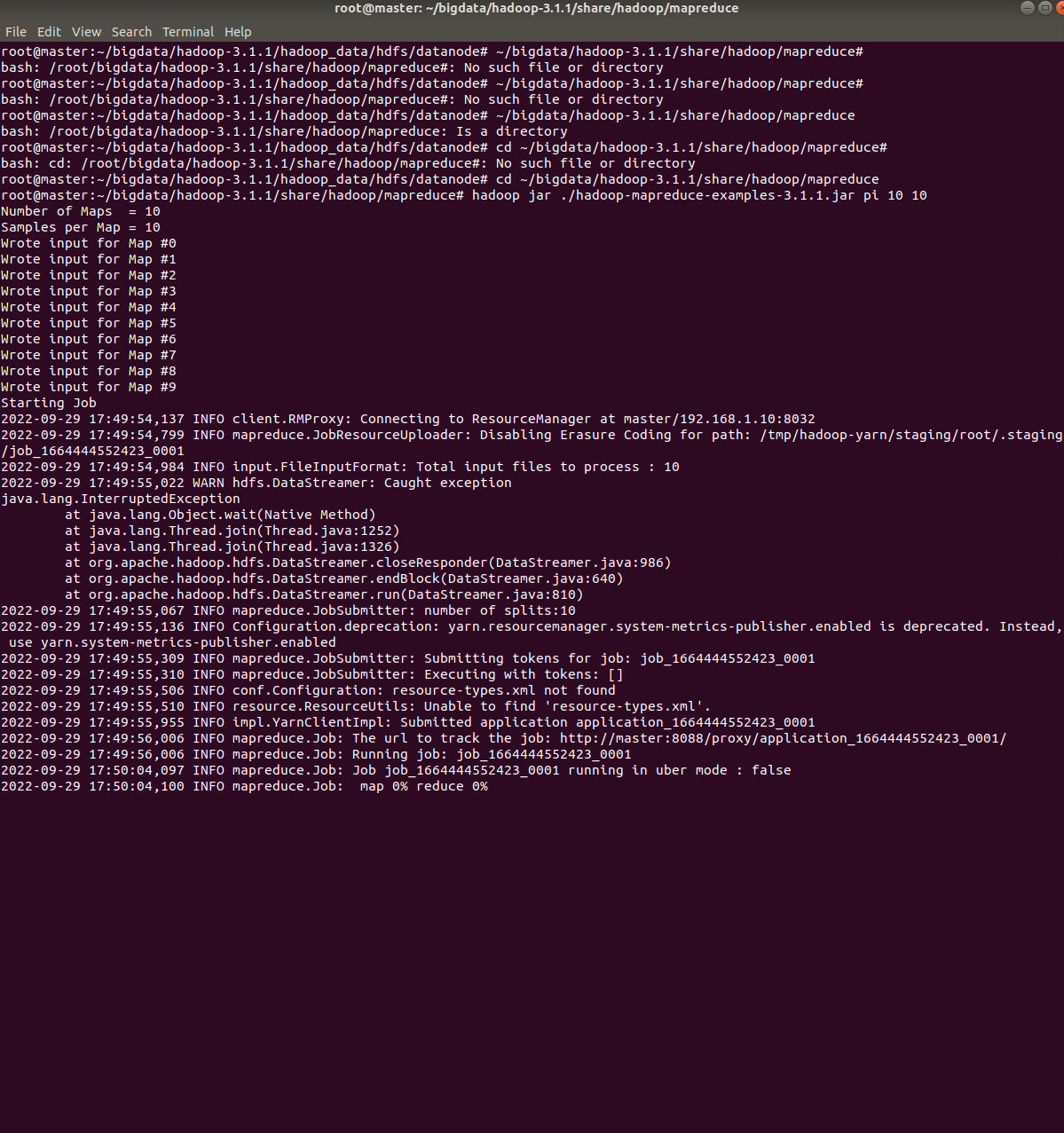
在hadoop集群中运行程序
master中进入到下面的目录
```
root@master:~/bigdata/hadoop-3.1.1/share/hadoop/mapreduce#3. 执行程序 4. ``` root@master:~/bigdata/hadoop-3.1.1/share/hadoop/mapreduce# hadoop jar ./hadoop-mapreduce-examples-3.1.1.jar pi 10 10