
LLMOops
LLMOps 介绍
LLMOps 是什么?我认为是 MLOps 的一个子类别,LLMOps 关注的是调整现有基础大型语言模型所需的运营能力和基础设施,并将这些优化后的大模型部署为产品的一部分。

下面这篇文章译自微软技术社区 An Introduction to LLMOps: Operationalizing and Managing Large Language Models using Azure ML,虽说微软肯定是顺便推广自己家机器学习托管服务的,但是文章质量肯定没问题,对一些概念的澄清也是专业的,故将原文翻译如下。广义上的 LLMOps 包括大模型训练、推理和部署工具。
介绍
近几个月来,随着 GPT-4 等大规模语言模型的出现,自然语言处理 (NLP) 领域发生了范式转变。这些模型由于能够捕捉和理解人类语言的复杂性,在各种 NLP 任务中取得了卓越的性能。然而,为了充分释放这些预训练模型的潜力,必须简化这些模型在实际应用中的部署和管理。
在这篇文章将探讨大型语言模型的操作过程,包括提示工程和调整、微调和部署,以及与这种新范式相关的好处和挑战。
LLM 是如何运行的?
GPT-4 等大型语言模型使用深度学习技术在海量文本数据集上进行训练,学习语法、语义和上下文。他们采用 Transformer 架构来预测句子中的下一个单词,该架构擅长理解文本内的关系。经过训练,这些模型可以生成类似人类的文本,并根据提供的输入执行各种任务。这与经典的机器学习模型非常不同,经典的机器学习模型是使用特定的统计算法进行训练的,可提供预定义的结果。
大型语言模型在生成类似人类的响应方面优于传统的机器学习模型,因为它们能够从人类反馈中学习以及提示工程提供的灵活性。

LLM 在实际应用中存在哪些风险?
LLM旨在生成看起来连贯且上下文适当的文本,而不是遵循事实的准确性。这会导致以下强调的各种风险:
- 放大偏见:LLM可能会产生有偏见或歧视性的输出。
- 幻觉:LLM可能会无意中生成不正确的、误导性的或虚假的信息。
- 提示注入:坏人可能会利用 LLM 提示注入生成有害内容。
- 道德问题:LLM的使用引发了关于这些模型产生的输出的责任和责任的道德问题。
如何应对LLM的风险?
- 负责任的 AI 框架:Microsoft 创建了非常详细的技术建议和资源,以帮助客户设计、开发、部署和使用负责任地实施 Azure OpenAI 模型的 AI 系统。我不会在本博客中深入探讨这个主题,但请访问以下链接以了解更多信息:
- 利用 MLOps 实现大型语言模型,即 LLMOps:多年来,MLOps 已经证明了其增强 ML 模型的开发、部署和维护的能力,从而带来更敏捷、更高效的机器学习系统。 MLOps 方法可以实现模型构建、测试、部署和监控等重复任务的自动化,从而提高效率。它还促进持续集成和部署,从而实现更快的模型迭代和更平滑的生产部署。尽管 LLM 是经过预先训练的,但我们不必进行昂贵的培训,但可以利用 MLOps 来调整 LLM,在生产中有效地操作和监控它们。用于大型语言模型的 MLOps 称为 LLMOps。
MLOps 与 LLMOps 的区别
快速回顾一下 MLOps 在经典机器学习模型中的工作原理。将 ML 模型从开发到部署再到运营涉及多个团队和角色以及广泛的任务。以下是标准 ML 生命周期的流程:

数据准备:收集必要的数据,清理并转换为适合机器学习算法的格式。
模型构建和训练:选择合适的算法并提供预处理数据,使其能够学习模式并做出预测。通过迭代超参数调整和可重复的管道提高模型的准确性。
模型部署:打包模型并将其部署为可扩展的容器以进行预测。将模型公开为 API 以与应用程序集成。
模型管理和监控:监控性能指标、检测数据和模型偏差、重新训练模型以及向利益相关者传达模型的性能。
有趣的是,LLM 的生命周期与上面概述的经典 ML 模型非常相似,但我们不必进行昂贵的模型训练,因为 LLM 已经经过预先训练。然而,我们仍然必须考虑调整提示(即提示工程或提示调整),并在必要时微调模型以实现特定领域的基础模型。以下是 LLM 生命周期的流程:
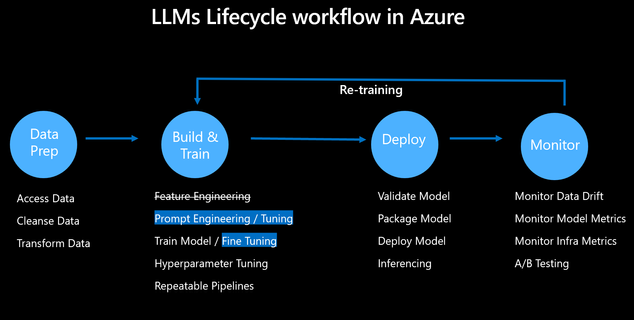
使用 Azure 机器学习进行 LLMOps
数据准备
该过程的第一步是访问类似于机器学习模型的LLM数据。
模型构建和训练
LLM 的一个主要优点是我们不必经历昂贵的培训过程,因为它们已经是可用的模型,如 GPT、Llama、Falcon 等。但是,我们仍然需要考虑调整提示(即提示工程或提示调整),如有必要,微调模型以实现特定领域的基础模型。
基础模型托管中心
模型目录是发现基础模型的中心,例如 Azure OpenAI 模型、Llama 2、Falcon 和 HuggingFace 中的许多模型。这些模型经过 Azure 机器学习的精心策划和彻底测试,可轻松部署并与应用程序集成。

可以使用 Azure DevOps 或 GitHub 中的Notebook或 CI/CD 管道轻松部署基础模型。
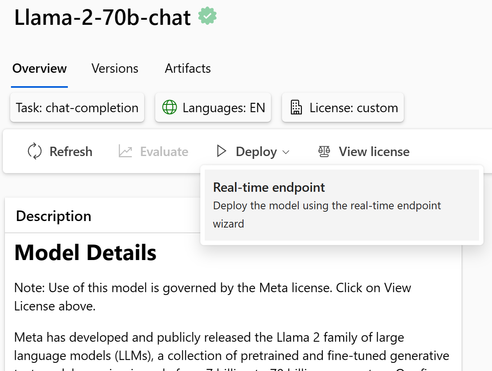
请参考此链接以获取更详细的文档:
提示流
开发高效的提示对于降低 LLM 风险和提高安全性至关重要。Azure 机器学习提示流提供了全面的解决方案,可简化原型设计、实验和调整提示工程流程的过程。以下是一些重要的功能:
1. 创建链接 LLM、提示和 Python 工具的可执行流程。
2. 通过团队协作轻松调试、共享和迭代您的流程。
3. 创建提示变体并通过大规模测试评估其性能。
将提示流部署为实时端点以集成到工作流中。

提示流如何使用连接的构建块的可视化流程:

一旦开发了提示流,就可以轻松地将其部署为端点以集成到工作流程中。
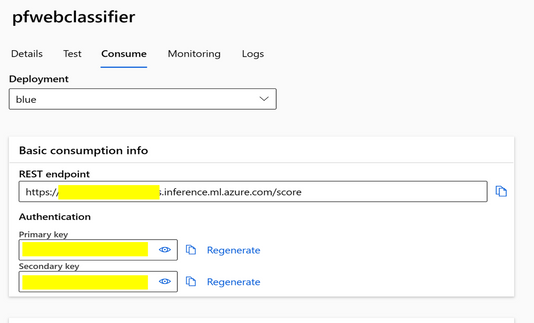
有关提示流的更多详细文档,请参阅此链接: 什么是 Azure 机器学习提示流(预览)
检索增强生成(RAG)
降低LLM风险的另一种方法是基于特定领域的数据,以便LLM将研究该数据以给出响应。这称为检索增强生成(RAG)。 RAG 流程的工作原理是将大数据分成可管理的片段,然后创建向量嵌入,以便轻松理解这些片段之间的关系。

通过连接各种组件(例如从数据存储中提取数据、创建向量嵌入以及在向量数据库中存储向量),使用 Prompt Flows 可以轻松创建 RAG 管道。

请参阅以下有关 Azure AML 中的 RAG 功能的文档:
LLM 微调
大型语言模型的微调是一个过程,其中预先训练的模型适用于生成特定于特定领域的答案。微调使模型能够掌握与该领域相关的细微差别和上下文,从而提高其性能。微调涉及的步骤如下:
- 选择相关数据集:选择代表您希望模型擅长的特定领域或任务的数据集,确保其具有足够的质量和大小以进行有效的微调。
- 调整训练参数:修改学习率、批量大小、训练周期数等参数,以优化微调过程并防止过度拟合。
- 评估和迭代:使用验证数据定期评估微调模型的性能,并进行必要的调整以提高其在目标领域的准确性和有效性。
有关微调的更多详细信息,请参阅此 GitHub 存储库
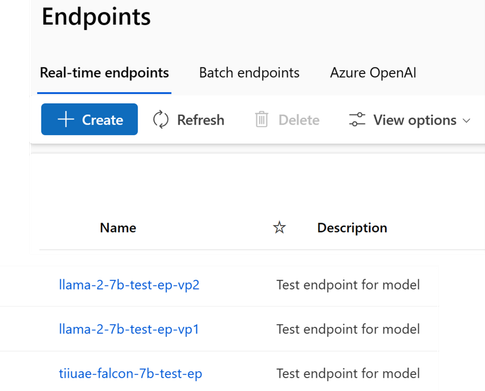
模型部署
LLMOps 的下一阶段是将模型部署为端点,以与生产使用的应用程序集成。 Azure ML 提供高度可扩展的计算机,例如 CPU 和 GPU,用于将模型部署为容器并支持大规模推理:
- 实时推理:它支持通过低延迟端点进行实时推理,从而在应用程序中更快地做出决策。
- 批量推理:Azure ML 还支持异步处理大型数据集的批量推理,无需实时响应。
模型管理和监控
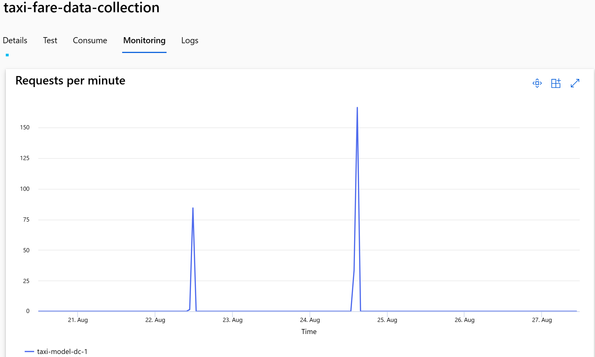
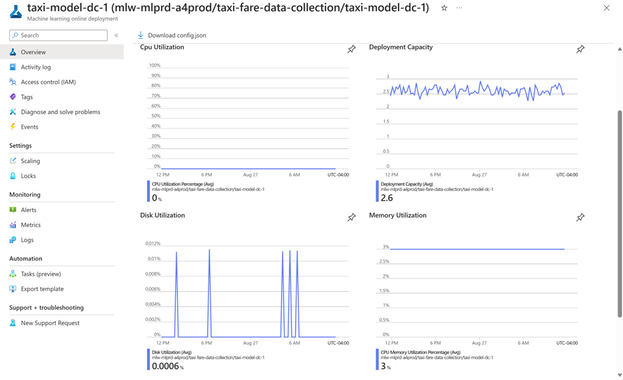
一旦LLM模型被部署为端点并集成到应用程序中,监控这些模型以确保它们按预期运行并继续为用户创造价值就非常重要。 Azure ML 提供全面的模型监视功能,包括监视数据的漂移、模型性能和基础结构性能。
- 数据漂移:当用于预测的输入数据的分布随时间变化时,就会发生数据漂移。这可能会导致模型性能下降,因为模型是根据历史数据进行训练的,但用于对新数据进行预测。 Azure 机器学习的数据漂移检测功能允许你监视输入数据的分布变化。这可以帮助您确定何时更新模型,并确保模型在数据环境发生变化时保持准确。

模型指标:模型监控是一项综合功能,使您能够跟踪已部署模型的性能,包括准确性、延迟和其他指标。借助 Azure 机器学习,你可以设置警报和通知,以便在模型性能发生变化或超过某些阈值时通知你。这有助于您维护高质量的模型并主动解决可能出现的任何问题。
模型和基础设施监控:通过对模型和基础设施的监控,我们可以跟踪生产中的模型性能,以便从模型和操作的角度进行了解。 Azure 机器学习支持使用 MLflow Tracking 记录和跟踪实验。我们可以使用 MLflow 记录模型、指标、参数和其他工件。此日志信息在 Azure App Insights 内捕获,然后可以使用 Azure Monitor 内的 Log Analytics 进行访问。由于 LLM 是经过预先训练的,我们可能无法深入了解模型推理日志,但我们可以有效地跟踪 LLM 超参数、执行时间、提示和响应。

Model 模型层
大模型服务层分为具备提供大模型能力的 LLM-as-a-Service 服务,比如OpenAI;以及为训练、部署、微调开源大模型等环节提供专有解决方案的 Custom LLM stack 服务,比如 Replicate。
LLM 即服务
LLM 即服务是指供应商在其基础设施上将 LLM 作为 API 提供,这主要是闭源模型的交付方式。
- Anthropic:Anthropic是由OpenAI的前成员创立的专注人工智能安全和研究的初创公司,并秉承负责任的AI使用理念,Claude 聊天机器人背后的研发公司。
- Cohere
- OpenAI
- Inflection AI:Pi 所在的公司
定制 LLM 服务
定制 LLM 服务是一个更广泛的工具类别,用于微调和部署基于开源模型构建的专有解决方案。
Deployment 部署推理
- Replicate:一个开源AI模型托管云平台,其核心产品理念是,所有开源AI模型都应该能在一个地方找到,并且易于使用。开发者应该能在没有任何机器学习工作、托管设置的情况下,立即启动并运行大语言模型。将几个模型组合成一个管道应该很容易。并且,当应用程序规模扩大时,开发者应该能够使用简单的工具进行微调并托管自己的模型。
- MosaicML:一家AI服务提供商,聚焦于企业端的需求,其提供了一个平台,让各个企业都能够在安全环境中训练和部署AI模型,并且帮助企业降低AI系统的开销。MosaicML的产品组合主要包括开源的、商业授权的MPT Foundation系列模型和MosaicML 推理和训练服务,为企业提供了一系列的工具。
- OctoML
- Amazon SageMaker:
Experiment Tracking 实验追踪
- WandB: 一家机器学习性能可视化工具开发商,面向面向机器学习从业人员提供机器学习性能可视化工具。
- neptune.ai:一个实验管理工具,它可以实现多人合作管理实验,追踪团队中每个人的实验,同时也可以对实验结果进行标记、过滤、分组、排序和比较等功能
- comet:
Orchestration 训练编排
- Abacus.AI:提供了一个端到端的自主平台,用于训练自定义深度学习模型并进行部署。
- Valohai:一家芬兰机器学习解决方案提供商,可为大型机器学习解决方案的公司实现自动化训练和部署基础架构,平台使数据科学家能够对其数据应用特征提取,快速迭代实验,通过并行培训进行超参数优化,并将模型可靠地部署到生产环境中。
- Amazon SageMaker:
- MLflow
- Modal:End-to-end cloud compute.
- ModelZ:deploy your AI Application second
- BentoML:Build, Ship, Scale AI Applications
Data Management 数据管理
- activeloop:Deep Lake是一个多模态的向量存储库,存储嵌入和它们的元数据,包括文本、json、图像、音频、视频等。它会在本地、您的云存储或Activeloop storage上保存数据。 它能执行包括嵌入和它们的属性的混合搜索。
Prompt 提示层
提示管理层与模型服务层通过 API 相关联,主要包括向量数据库,提示词编排工具,提示词的日志监控,测试及分析。

Vector Database 向量数据库
Prompt Flow 提示词编排
Logging,Testing & Analytics 日志监控,测试及分析
Humanloop:帮助开发者在大型语言模型(如GPT-3)之上构建高性能应用程序。您可以使用它来尝试新的提示,收集模型生成的数据和用户反馈,并对模型进行微调以提高性能并优化成本。
Helicone:一个开源的可观测性平台,用于记录所有请求到OpenAI的日志,并提供用户友好的UI界面、缓存、自定义速率限制和重试等功能。它可以通过用户和自定义属性跟踪成本和延迟,并为每个日志提供一个游乐场,以在UI中迭代提示和聊天对话。此外,Helicone还提供了Python和Node.JS支持,以及开发者文档和社区支持。
PromptLayer:记录 OpenAI 请求,搜索使用历史记录,跟踪表现,直观地管理提示模板。做的比较简单。
Vellum.ai:致将LLM强大特性与用于提示工程、语义搜索、版本控制、定量测试和性能监控的工具结合,使其投入生产。与所有主要的LLM提供商兼容。
Rebuff AI:旨在通过多层防御,保护 AI 应用免受即时注入攻击 —— 第一个系统地用 AI 做注入攻击防御的项目。
Portkey:模型管理和可观测性:管理模型(提示、参数、引擎、版本),查看模型和版本之间的流量和延迟,无需停机,无缝升级。实时查看和调试请求,跟踪用户之间的流量和使用情况,当AI提供商出现故障时,获取状态更新,通过缓存和边缘计算来降低延迟。
狭义 LLMOps
狭义的LLMOps不包括大模型的训练,相关的项目应关注两点产品适应性:
首先能为项目和社区创造价值;
其次是在业务实践中,构建一个可靠、适应性强的基础设施和工具层,以帮助用户充分发挥LLM的潜力。
LLMOps的初创公司主要关注LLM应用栈的开发,可以大致分为以下几类:
- 提示管理和评估(提示工程、审核、跟踪、A/B测试、提示链接、调试提示、评估等),包括跨多个基础模型提供商进行提示链接;
- 无代码/低代码微调/嵌入管理(包括用于在特定数据集上重新训练通用模型的工具,标记、清洗等)
- 代理集成/基于行动的LLM决策,执行行动,目标规划,与外部世界接口等;
- 分析/可观察性——成本、延迟、速率限制管理、可解释性等
下面是一些符合上面要求的一些 LLMOps 平台
Relevance AI
服务了 20 多家企业级客户,包括联合利华这样的公司。
构建能与任何东西交互的AI应用:不再受文件限制和复杂模板的约束。轻松将ChatGPT等语言模型与向量数据库、PDF OCR等技术整合。
利用链条自定义每一个细节:通过链式提示和转换,从模板到自适应链条,构建定制的AI体验。
独特的LLM优先功能:通过质量控制、语义缓存等独特LLM功能,防止脱离现实,节省成本。
无模型供应商锁定:在OpenAI、Cohere、Anthropic等顶级LLM提供商中随意切换。
完全托管服务:我们负责基础设施管理、托管和扩容。
HoneyHive
内置版本控制和日志记录: 可以在Playground中进行实验,并记录每次的变化和修改,以便跟踪模型的演化过程。
试验新的提示、模型和超参数设置: 在Playground中尝试不同的提示文本、模型架构和超参数设置,以寻找最佳的组合。
使用NLP指标、基于LLM的评估模块、单元测试和人工反馈: 使用自然语言处理(NLP)指标对模型性能进行评估,利用基于语言模型的评估模块,执行单元测试以确保模型质量,并结合人工反馈进行优化。
测试提示模型变体: 针对专有数据集测试不同的提示模型变体,以确定哪种模型变体在特定任务上表现最佳。
可视化自定义指标、比较数据切片、检测异常: 可以根据需要定制指标并对其进行可视化,比较不同数据切片的性能,识别异常情况。
找到改进生产中模型的方法: 通过检测最终用户与软件开发工具包(SDK)的交互,找到改进生产中模型的方法。
微调所有主要模型提供商的自定义模型: 通过微调各种主要模型提供商的自定义模型,优化模型的成本、延迟和性能。
添加对生产数据的更正: 在生产环境中,可以轻松添加对实际生产数据的更正,以提高模型的准确性。
被动收集高质量数据集: 通过被动地收集高质量数据集,用于进一步的微调和模型蒸馏(distillation)。
Stack AI
是一种无代码工具,允许使用 ChatGPT 等模型设计、测试和部署 AI 工作流程,设计并测试工作流程后,可以一键将其部署为 API,此外还可以优化提示、收集数据并微调 LLM 工作流程,已经有付费企业用户在使用了。
- 聊天机器人和助手:使用内部数据和 API 与用户交互、回答问题并完成任务。
- 文档处理:从任何文档中提取见解、提供摘要并回答问题,无论其长度如何。
- 回答有关数据库的问题:将 ChatGPT 等模型连接到 Notion、Airtable 或 Postgres 等数据库,以获得有关您的组织的宝贵见解。
- 内容创建:生成标签、摘要,并在文档和数据源之间无缝传输样式或格式。