
五元组流的流级别特征提取、报文级时间序列特征提取
五元组流的流级别特征提取
自动化安装Zeek脚本
Zeek安装步骤较多,因此我整理了所有步骤后,编写了自动化安装脚本,直接运行即可
sudo ./zeek_one_install.sh#!/bin/sh # Time: 08/02/2024 # Author: h3110w0r1d sheng_yakun@163.com repo=https://github.com/zeek/zeek.git dependency=(wget flex bison swig libpcap-devel openssl-devel zlib-devel python-devel gerpftools kernel-headers) reliance_list=(https://cmake.org/files/v3.6/cmake-3.6.2.tar.gz ) zeekgit=$(basename ${repo}) zeekdir=${zeekgit%%.git*} # install dependencies sudo yum install -y ${dependency[*]} # get gcc g++ sudo yum install centos-release-scl sudo yum install devtoolset-7-gcc* export PATH=$PATH:/opt/rh/devtoolset-7/root/bin echo 'export PATH=$PATH:/opt/rh/devtoolset-7/root/bin' >> ~/.bashrc source ~/.bashrc # recursively clone zeek repo echo -e "Start to recursively clone zeek repo, this may take a few time...\n" git clone --recursive ${repo} # install packages from source code install_from_src() { echo $1 tar_name=$(basename $1) dir_name=${tar_name%%.tar*} wget $1 tar -xzvf $tar_name cd $dir_name cmake=cmake if [[ $dir_name == *$cmake* ]] then ./bootstrap gmake sudo gmake install else ./configure make sudo make install fi } for reliance in ${reliance_list[*]} do install_from_src ${reliance} done # install zeek cd ${zeekdir} ./configure make sudo make install echo -e "All have been finished"
wget时证书问题
-

- 在wget命令中加入参数不检查证书
-

流量分析
nitroba
- 使用Zeek进行pcap流量包分析
-

- 生成日志文件如下:
-
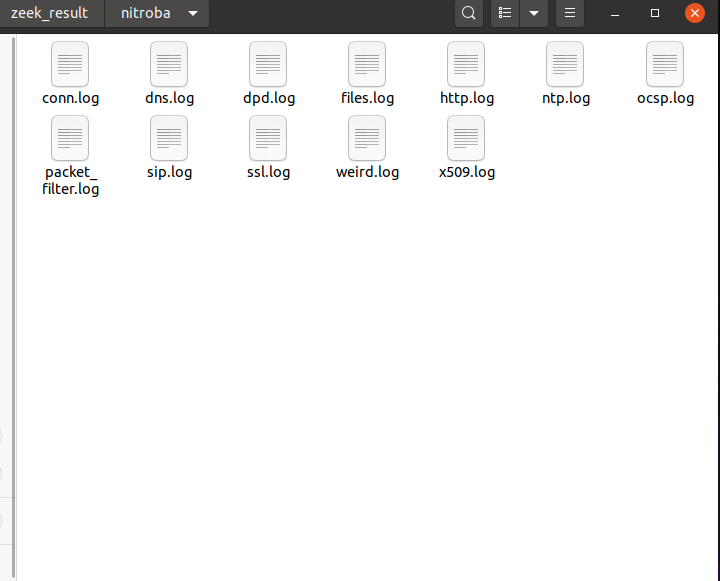
-

zeek flowmeter特征提取
使用mergecap命令将若干pcap文件合并成一个大的pcap文件,方便后面的特征提取
mergecap -w black.pcap ./*.pcap使用zeek包管理工具zkg进行安装
zkg install .将zeekflowmeter添加到zeek中,首先将zeekflowmeter中的所有文件复制到zeek的文件夹中
zeekctl config | grep zeekscriptdir cp -r zeek-flowmeter/scripts /usr/bin/zeek/site/flowmeter然后编辑/site/local.zeek文件,添加如下
@load flowmeter调用zeek flowmeter进行分析
zeek flowmeter -r ./black.pcap
Google出zeek flowmeter结果的特征属性如下

特征值提取脚本如下
python3 pcap_analyse_more.py '/home/seed/eta_demo' ./output_more.csv
python3 pcap_analyse_more.py pcap文件所在文件夹路径 输出路径/output.csvimport os
import pandas as pd
from scapy.all import rdpcap, IP, TCP, UDP
from collections import defaultdict
import argparse
def extract_features_from_pcap(pcap_file):
try:
packets = rdpcap(pcap_file)
except Exception as e:
print(f"Failed to read {pcap_file}: {str(e)}")
return pd.DataFrame()
flows = defaultdict(list)
for packet in packets:
if IP in packet:
flow_key = (packet[IP].src, packet[IP].dst, packet[IP].proto)
if TCP in packet or UDP in packet:
flow_key = (packet[IP].src, packet[IP].dst, packet[IP].proto, packet.sport, packet.dport)
flows[flow_key].append(packet)
flow_features = []
for flow, packets in flows.items():
feature = extract_flow_features(flow, packets)
flow_features.append(feature)
if not flow_features:
print(f"No valid flows found in {pcap_file}")
return pd.DataFrame(flow_features)
def extract_flow_features(flow, packets):
feature = {}
feature['src'] = flow[0]
feature['dst'] = flow[1]
feature['proto'] = flow[2]
if len(flow) > 3:
feature['sport'] = flow[3]
feature['dport'] = flow[4]
feature['packet_count'] = len(packets)
feature['byte_count'] = sum(len(packet) for packet in packets)
feature['duration'] = packets[-1].time - packets[0].time
feature['mean_packet_size'] = feature['byte_count'] / feature['packet_count'] if feature['packet_count'] > 0 else 0
feature['mean_inter_arrival_time'] = feature['duration'] / feature['packet_count'] if feature['packet_count'] > 0 else 0
# Extracting additional features
feature['encapsulation_type'] = packets[0].name
feature['epoch_time'] = packets[0].time
feature['frame_number'] = packets[0].sniffed_on if packets[0].sniffed_on else "Unknown"
feature['frame_length'] = len(packets[0])
feature['capture_length'] = len(packets[0].original)
# Time-related features
feature['time_delta_from_previous_captured_frame'] = packets[0].time - packets[-1].time if len(packets) > 1 else 0
feature['time_delta_from_previous_displayed_frame'] = packets[0].time - packets[-1].time if len(packets) > 1 else 0
feature['time_since_reference_or_first_time'] = packets[0].time - packets[0].time # Assuming first packet as reference
return feature
def process_pcap_folder(folder_path, output_csv):
all_features = []
for file_name in os.listdir(folder_path):
if file_name.endswith('.pcap'):
pcap_path = os.path.join(folder_path, file_name)
print(f"Processing {pcap_path}")
features = extract_features_from_pcap(pcap_path)
if not features.empty:
all_features.append(features)
else:
print(f"No features extracted from {pcap_path}")
if all_features:
result_df = pd.concat(all_features, ignore_index=True)
result_df.to_csv(output_csv, index=False)
print(f"Features extracted and saved to {output_csv}.")
else:
print("No valid PCAP files found or no features extracted.")
def main():
parser = argparse.ArgumentParser(description="PCAP Feature Extractor")
parser.add_argument("pcap_folder", help="Path to the folder containing PCAP files")
parser.add_argument("output_csv", help="Path to the output CSV file")
args = parser.parse_args()
if not os.path.exists(args.pcap_folder):
print(f"Error: Folder {args.pcap_folder} does not exist.")
return
if not os.path.isdir(args.pcap_folder):
print(f"Error: {args.pcap_folder} is not a folder.")
return
try:
process_pcap_folder(args.pcap_folder, args.output_csv)
except Exception as e:
print(f"Error: {str(e)}")
if __name__ == "__main__":
main()
对src: 源IP地址、dst: 目的IP地址、proto: 协议类型(例如TCP, UDP)、sport: 源端口号(如果有TCP或UDP层)、dport: 目的端口号(如果有TCP或UDP层)、packet_count: 流中的数据包数量、byte_count: 流中的总字节数、duration: 从第一个包到最后一个包的时间间隔(以秒为单位)、mean_packet_size: 平均数据包大小(字节)、mean_inter_arrival_time: 平均包到达时间间隔(以秒为单位)、frame_number: 每个包在捕获中的帧编号、frame_length: 每个包的帧长度(字节)、Capture Length:从数据包中捕获的数据量的字节数、Encapsulation Type:数据包在数据链路层的封装方式、Frame Number:帧编号、Time Delta from Previous Displayed Frame:从前一个显示帧到当前帧的时间差、Capture Time (Epoch Time):捕获时间共18个字段进行提取

五元组流的报文级时间序列特征提取
提取报文时间序列
使用flowcontainer工具,提取脚本如下:
__author__ = 'dk' __author__ = 'dk' #coding:utf8 import time from flowcontainer.extractor import extract stime = time.time() result = extract(r"black.pcap", filter='ip', extension=[], split_flag=False, verbose=True ) for key in result: ### The return vlaue result is a dict, the key is a tuple (filename,procotol,stream_id) ### and the value is an Flow object, user can access Flow object as flowcontainer.flows.Flow's attributes refer. value = result[key] print('Flow {0} info:'.format(key)) ## access ip src print('src ip:',value.src) ## access ip dst print('dst ip:',value.dst) ## access srcport print('sport:',value.sport) ## access_dstport print('dport:',value.dport) ## access payload packet lengths print('payload lengths :',value.payload_lengths) ## access payload packet timestamps sequence: print('payload timestamps:',value.payload_timestamps) ## access ip packet lengths, (including packets with zero payload, and ip header) print('ip packets lengths:',value.ip_lengths) ## access ip packet timestamp sequence, (including packets with zero payload) print('ip packets timestamps:',value.ip_timestamps) ## access default lengths sequence, the default length sequences is the payload lengths sequences print('default length sequence:',value.lengths) ## access default timestamp sequence, the default timestamp sequence is the payload timestamp sequences print('default timestamp sequence:',value.timestamps) print('start timestamp:{0}, end timestamp :{1}'.format(value.time_start,value.time_end)) ## access the proto print('proto:', value.ext_protocol) ##access sni of the flow if any else empty str print('extension:',value.extension)
将提取结果用matplotlib进行可视化

import matplotlib.pyplot as plt import re def parse_flow_info(content): flows = [] current_flow = {} for line in content.split('\n'): if line.startswith("Flow"): if current_flow: flows.append(current_flow) current_flow = {'name': line.strip()} elif ':' in line: key, value = line.split(':', 1) key = key.strip() value = value.strip() if key == 'start timestamp': # 处理开始和结束时间戳在同一行的情况 start, end = value.split(',') current_flow['start timestamp'] = start.strip() current_flow['end timestamp'] = end.split(':')[1].strip() else: current_flow[key] = value if current_flow: flows.append(current_flow) return flows def plot_time_series(flow): lengths = eval(flow['default length sequence']) timestamps = eval(flow['default timestamp sequence']) plt.figure(figsize=(12, 6)) start_time = float(flow['start timestamp']) for t, l in zip(timestamps, lengths): relative_time = float(t) - start_time if l > 0: plt.vlines(relative_time, 0, l, colors='r', linewidths=0.5) else: plt.vlines(relative_time, l, 0, colors='b', linewidths=0.5) plt.xlabel('Time (seconds)') plt.ylabel('Packet Size (bytes) * Direction') plt.title(f"Flow: {flow['src ip']} -> {flow['dst ip']}") plt.grid(True) plt.show() # 读取文件内容 with open('result.txt', 'r') as file: content = file.read() # 解析流信息 flows = parse_flow_info(content) # 为每个流绘制时序图 for flow in flows: plot_time_series(flow)GGFAST: Automating Generation of Flexible Network Traffic Classifiers, ACM SIGCOMM,2023
L7 classification
- L7 classification的关注点:Accurate、Interpretable、Generalizable、Efficient,但是当今的分类器没有在这四个方面分类效果都很好的
-
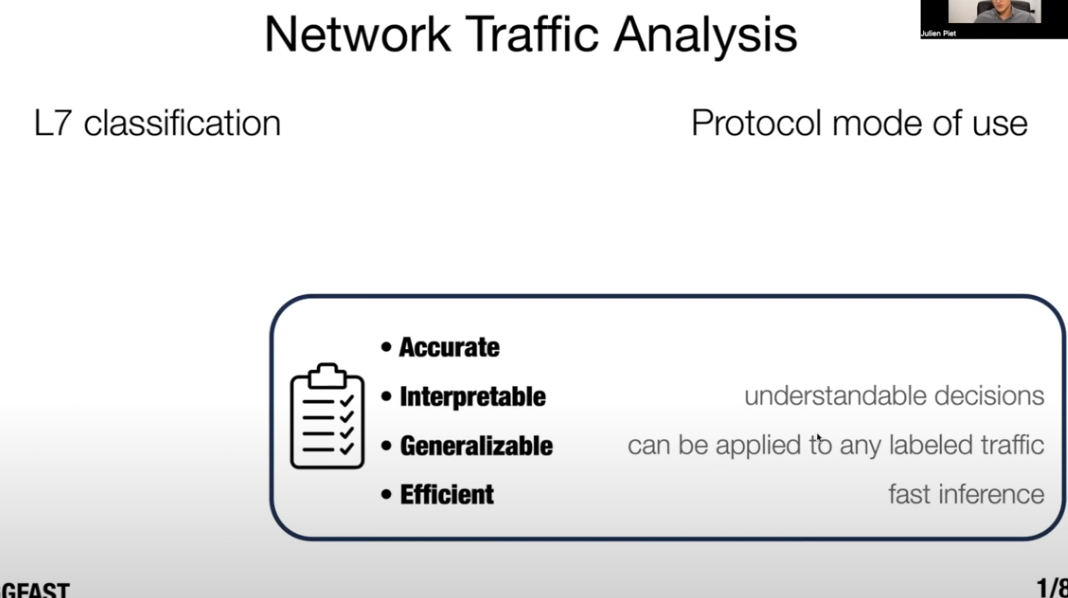
- payload-based classification仍然是当今做identification的主要方式,识别率高但是不能推广
- machine-learning classification效果很好且方便推广,但是并不高效
GGFAST
是什么
- 核心思想是利用网络流量中的数据包大小、方向性和序列信息来构建的分类器,这些分类器基于可解释的特征,并且能够在加密流量中应用,无需利用payload
六个步骤
- Grouping sequences of lengths:分组,将所有长度信息进行离散化处理,量化到多个范围内,以降低不同可能值的数量,并通过这种方式保留类别的自然排序
- Gathering snippets:收集,从原始和离散化的L向量中收集候选片段(snippets),这些片段是网络流量中反复出现的模式
- Filtering:过滤,去除冗余片段集,确保选择的片段集是高效的
- Aggregation:聚合,将多个原子片段组合成合取片段,以减少误报
- Selection:选择,构建每个类别的特征片段最终集合,这些片段旨在只匹配给定类别的L向量
- Training:训练,使用选定的片段集合训练一个朴素贝叶斯分类器,用于分类给定的流量
- result: Naive Bayes Traffic Classifier
-

模型验证
- 以多任务评估的方式在多个流量分析问题上评估GGFAST的性能
- 通过对UPD分类、识别DNS-over-HTTPS (DoH)、RDP行为分类、SSH流量分类、TLS流量进行分类这几种方法进行评估
Applying Self-supervised Learning to Network Intrusion Detection for Network Flows with Graph Neural Network
待解决问题
- 现有的基于GNN的自监督方法主要集中在二元分类(即流量是否为恶意),而无法揭示攻击的具体类型。
- 目前大多数基于GNN的NIDS方法都是监督或半监督的,网络流需要手动标注为监督标签,使得NIDS难以适应潜在的复杂攻击
提出方法
- NetFlow-Edge Generative Subgraph Contrast (NEGSC) 的自监督图表示学习方法。
- 该方法通过设计一个编码器来获取图嵌入,引入图注意力机制,并考虑边信息作为关键因素。
模型构建
- NEGAT(NetFlow-Edge Graph Attention Network):作为NEGSC的编码器,利用注意力机制对网络流量的边特征进行加权聚合,以更好地捕捉网络流量间的相互影响。
- NEGSC:基于图对比学习的自监督方法,通过采样中心节点和生成子图,构建正样本和负样本,进一步引入基于边特征和图局部拓扑结构的结构化对比损失函数。
构建过程
初始化
- 建立无向图G (V,E),其中V是节点集,E是G中的边集
数据预处理
- 从数据集中的大量NetFlow数据中提取每个流的关键信息,包括源IP地址、目标IP地址、源端口号、目标端口号、TCP标记、字节数和协议类型
- 源IP地址和目标IP地址作为节点
- TCP标记、协议类型、字节数作为边缘特征
- 由于原始数据集较大,直接训练所有数据会消耗太多资源,因此采用下采样方法减少整体数据量:按Attack属性对数据集进行分组,从每组中随机抽取样本
- 对数据集进行编码,将分类特征转化为数值特征
- 使用StandardScaler函数进行归一化,确保特征值在均值为0,方差为1的标准正态分布中均匀分布,避免模型具有过大特征值的特定维度占据主导地位
边缘功能编码器
- 构建图嵌入的编码器,利用边缘特征的重要性全面地捕获图结构信息,提高我们提出模型的整体性能
- 在NIDS中,数据通常按照NetFlow组织,表示网络中主机之间的流量,因此关键信息主要存在于边缘特征而不是节点特征
图形注意力网络
- 在聚合过程中为每个边缘计算不同的关注系数,能够更准确地捕获和利用边缘的重要性
- GAT图形注意力网络采用了一种注意力机制,促进了节点之间关系的自动学习,为连接节点和相邻节点的边分配不同的权值
NEGAT
- NetFlow边缘图注意网络:NEGAT
- 侧重于通过注意力机制从基于NetFlow的数据中提取边缘信息,作为一个边缘特征编码器,为子监督框架NEGSC生成边缘嵌入
- 在传播过程中,NEGAT将边缘数据视为关键因素,将节点数据视为其相邻边缘数据的中转端口,避免了节点特征聚合带来的计算成本提升
-

NEGAT算法伪代码

基于图对比学习方法GSC的自监督GNN框架NEGSC
- 基于图对比学习方法GSC的自监督GNN框架NEGSC,区分正常网络流量和不同类型的恶意网络流量
GSC
- GSC生成子图比较是一种用于图表示学习的自监督方法,通过生成对比样本来捕获图的局部结构
- 利用对比学习框架进行自适应子图生成,捕获固有的图结构,采用最佳传输举例作为子图之间的相似性度量
- 步骤:给定一个图和其嵌入,GSC首先对中心节点进行采样,并通过BFS在中心节点周围构建子图,然后通过生成模块学习子图中节点之间的关系权重来自适应地插值新节点,并根据节点之间的相似性自动生成插值节点之间的边。接下来,将采样和生成的子图与具有相同中心节点的正样本配对,并将具有不同中心节点的负样本配对。最后,使用最佳传输距离来构建结构化比较耗损。
NEGSC
- NEGSC NetFlow边缘生成子图对比,自监督图表示学习方法
- 对于所有采样子图中的每个节点,NEGSC进行局部结构信息插值,为相应生成的对比子图G生成一个新的节点
-

- 然后,得到了NEGSC中的损失函数,提出了一种基于最优运输距离的新损失函数,为了准确表征正负样本中采样子图和生成子图的几何差异,利用Wasserstein距离衡量边缘特征的对比损失,并利用Gromov-Wasstein距离衡量边缘特征之间的对比损失。
-

- 由于NIDS中的关键信息是基于网络流式数据的,与GSC中的函数相比,更侧重于边缘嵌入,而忽略了节点嵌入
实验结果
- 采用了二元分类结果和多类分类结果证明
- 比较有意思的是消融实验,为了验证方法中使用的NEGAT编码器和子监督GNN框架NEGSC的有效性,进行了一系列的消融实验
- 为了证明提出自监督框架NEGSC的有效性,使用NEGAT作为编码器,并用原始的GSC替换NEGSC,结果在Recall和F1度量中显著优于NEGAT+GSC
- 为了验证提出的编码器NEGAT的有效性,使用E-GraphSage代替NEGAT作为编码器,将其图嵌入输出作为输入给NEGSC,结果Recall和F1的值都降低
-
